Automatically Discover Website Connections Through Tracking Codes
Translations:

This article originally appeared on the AutomatingOSINT.com blog.
Fellow Bellingcat contributor Lawrence Alexander did some really interesting OSINT work on analyzing the hidden links between websites using tracking and analytics codes. In his how-to titled “Unveiling Hidden Connections With Google Analytics IDs” he shows how you can begin to see how websites are connected to one another using only the shared tracking code used by the website owner to track visitors to their sites. He also has an article where he puts these OSINT techniques to good use here. The question that Lawrence posed was how can we automate this retrieval?
Together we began, using Lawrence’s original Python code to begin collaborating on a tool that would extract tracking codes from target websites, and additionally use the Meanpath API to try to find additional domains that contain the same tracking code. Additionally he expanded his search from just Google Analytics to include Google AdSense, Amazon Affiliates, and AddThis.com tracking codes. The end product is a script that produces a graph file that can be loaded into Gephi so that you can explore the results. Let’s take a look at how we did this.
Meanpath API
Meanpath is a search engine that captures the various bits of code, CSS and HTML across hundreds of millions of websites. This enables you to search for bits of code that might be not be indexed by other search providers. Meanpath provides a free API that is accessible on Mashapehere. Go get yourself setup with a key, as it enhances our script’s ability to expand the search for common connections. Let’s get down to the code.
Installing Prerequisites
First off Lawrence chose to use the lxml library for parsing the HTML and we’re also going to be using NetworkX for generating the graphs. You are going to need to install both:
# pip install lxml
# pip install networkx
Coding It Up
Crack open your favourite IDE (it should be Wing), create a new file called tracking_codes.py (download the source from here) and start punching in the following code:

Beauty. So we setup with some imports and then do some argument parsing for the script. It allows you to specify a single domain (-d), a file that has a list of domains (-f) and optionally to search Meanpath (-mp). If you don’t already have your Mashape API key, you should grab one now and paste it between the quotes on line 18.
Let’s add some more code below what we’ve done so far:

Alright let’s examine what we have created here. We setup a dictionary called networks that is going to contain all the information we need in order to match the various tracking codes that websites use. Let’s look at the dictionary a bit closer:
networks[‘Google Analytics’] = {
“xpath” : “//script/text()”,
“regex” : “UA-(.+?)-“,
“search_prefix” : “UA-” }
- xpath – this is the parsing rule required to extract Google Analytics code. As you can see the //script/text() code will look at <script> HTML tags and extract the code contained within them.
- regex – this is the regular expression that gets used against the text returned from our XPath extraction. This regular expression is responsible for pulling out the actual tracking code.
- search_prefix – this is for searching in Meanpath. By having a prefix we add to each Meanpath request it will help to narrow down the results.
So you can see that we setup an entry in our networks dictionary for each advertising or analytics network that we want to look for as well as the rules for processing each specific network. This was all Lawrence’s work!
After our networks dictionary we just have some simple command line handling code. Now let’s put our Meanpath search function in place:
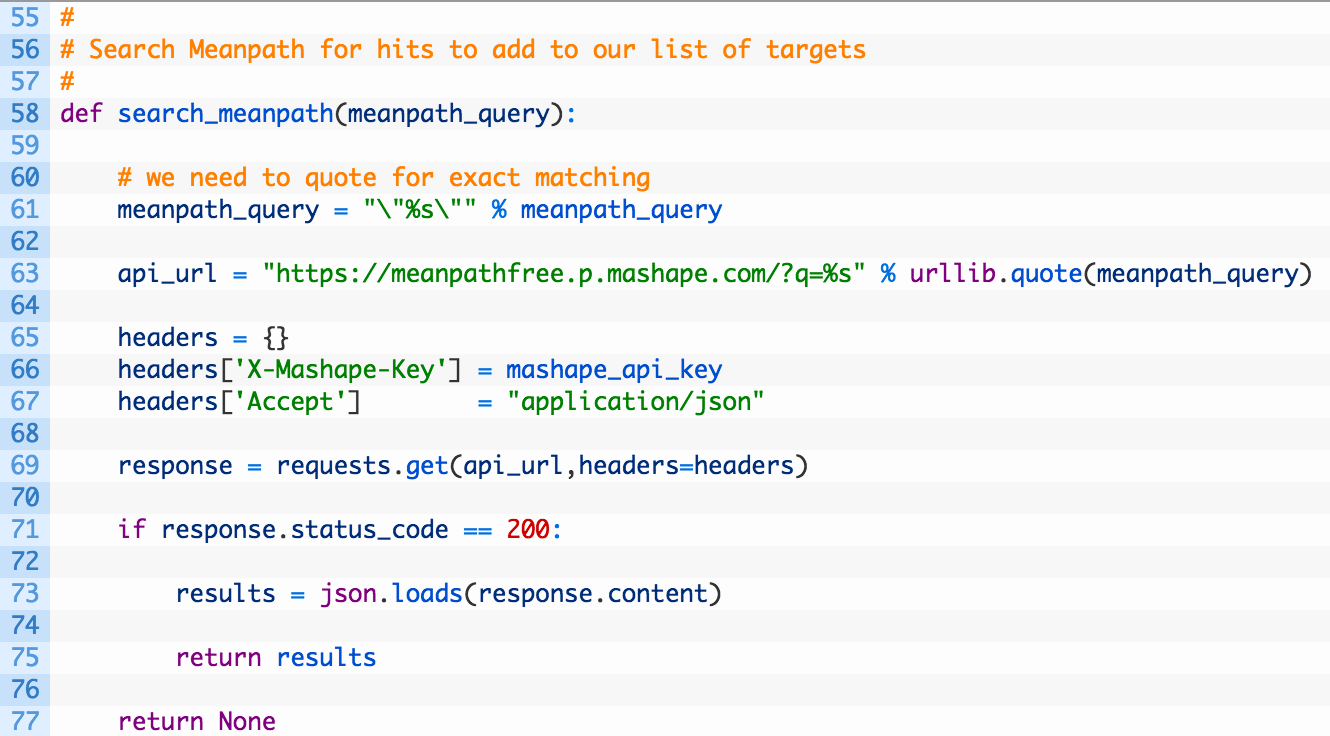
So let’s see what we did here:
- Line 58: we create our search_meanpath function that takes in meanpath_query that will be used for our search.
- Lines 61-63: we quote the search (61) to give us exact matches in the API (just like in Google) and then build our api_url (63) variable that will be the endpoint where we send our HTTP request.
- Lines 65-67: we create some custom headers for our HTTP request. Namely the X-Mashape-Key header is how we authenticate to the Mashape service.
- Lines 69-77: we are just sending off the response with our custom headers (69), and if we receive a valid response back (71) we parse the JSON returned (73) and return the results (75).
Now that we have the Meanpath plumbing in place, let’s build up our function that will extract our various tracking codes from the target websites we are after.

Let’s dig into this fairly hefty chunk of code:
- Line 82: we define our extract_tracking_code function that takes a tree object from the lxml module and an optional tracking_code parameter.
- Line 86: we are iterating over our dictionary of networks so that we can apply our network specific (Google Analytics, Google AdSense, etc.) rules to the HTML we have retrieved.
- Line 89: here we are using the xpath function to apply our XPath selector to the current HTML that has been passed in. We are retrieving the specific XPath rule from our networks dictionary.
- Lines 92-96: if our XPath selector was successful (92) we then begin iterating over the HTML elements that were returned (94) and then apply our regular expression to each element (96) in an attempt to extract the tracking code we are after.
- Lines 98-107: if we retrieved some tracking codes (98) we then test to see if the function was called with the tracking_code parameter (100). If the tracking_code parameter was passed in is detected in our list of tracking codes we just extracted using regular expressions (102) then we add it to our total list of hits (103). We have this logic here so that any results from Meanpath we are double verifying to ensure that if a tracking code is abc for example, we need to make sure that Meanpath isn’t just detecting the letters abc in the text of the target website. If the tracking_code parameter is not passed to our function (104) then we append it to our list of hits (105). When we are finished this process we simply return our list of hits (107).
Now let’s add another function to the mix that will deal with retrieving the webpage and doing the intial HTML parsing before handing off to the extract_tracking_code function that we just did.
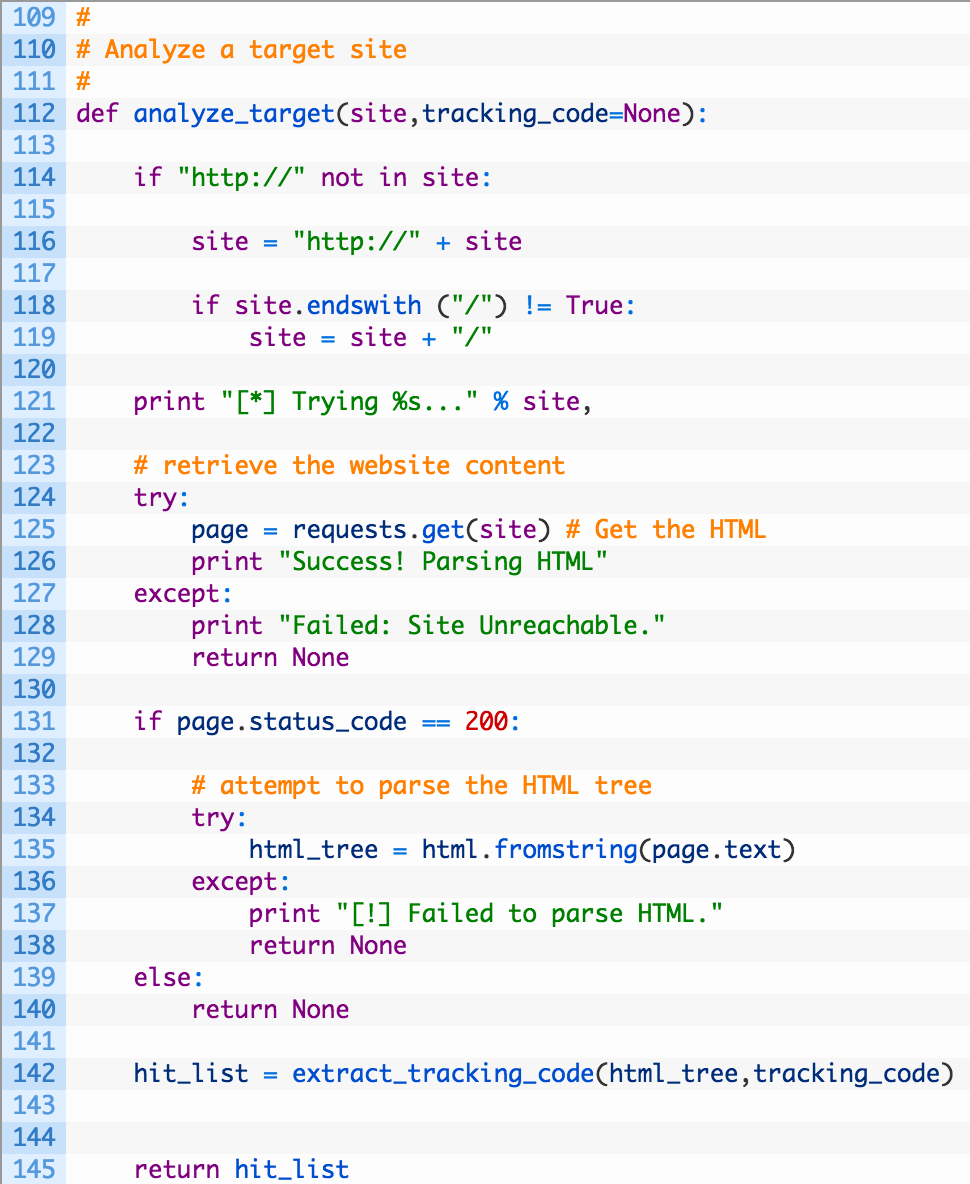
Let’s have a peek at the code.
- Line 112: we define our analyze_target function to receive a site parameter that will be our target website, and an optional tracking_code parameter that, if set, will be passed to our extract_tracking_code function.
- Lines 114-120: this is just some simple code to deal with formatting a domain that has been passed to our script so that it is a valid URL.
- Lines 121-129: here is where we are issuing the request (125) and if it fails we output an error message (128) and return None (129) to indicate that we failed to hit the target site.
- Lines 131-140: if we receive a valid response back from the target site (131) we then pass the retrieved HTML to the html module from lxml (135) so that it can parse the HTML document and return an html object.
- Line 142: if we have a valid HTML document we pass it off to our extract_tracking_code function that will return a list of tracking codes.
Ok! So this script is turning into a bit of a monster but we are nearly there. Let’s add some more code to begin finishing this up.
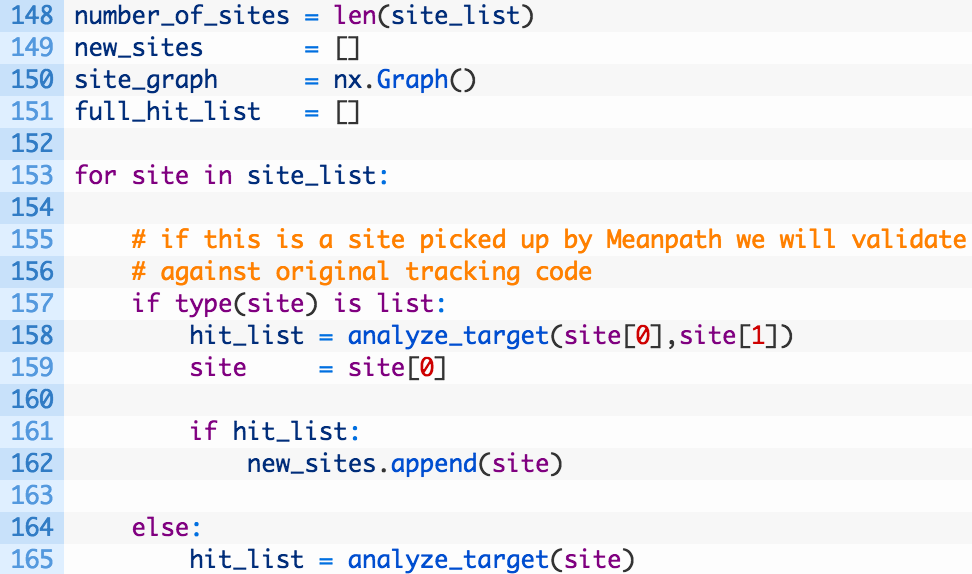
We’re getting there! Let’s have a look:
- Line 148-151: we are just setting up some variables to hold our hits, number of new websites discovered, our NetworkX graph object.
- Lines 153-165: we iterate over the list of sites passed to the script (153). If the site variable is a Python list (157) then we know that it was a new site picked up by Meanpath (you will see further down in the code why this is). We pass along the site name (site[0]) and the existing trackig code we detected (site[1]) and if we get tracking code hits (161) then we add the site to our list of new sites detected (162). If the site variable is just a domain we have received from our command line then we pass it along to the analyze_target function (165).
Let’s add some additional logic to this chunk of code.
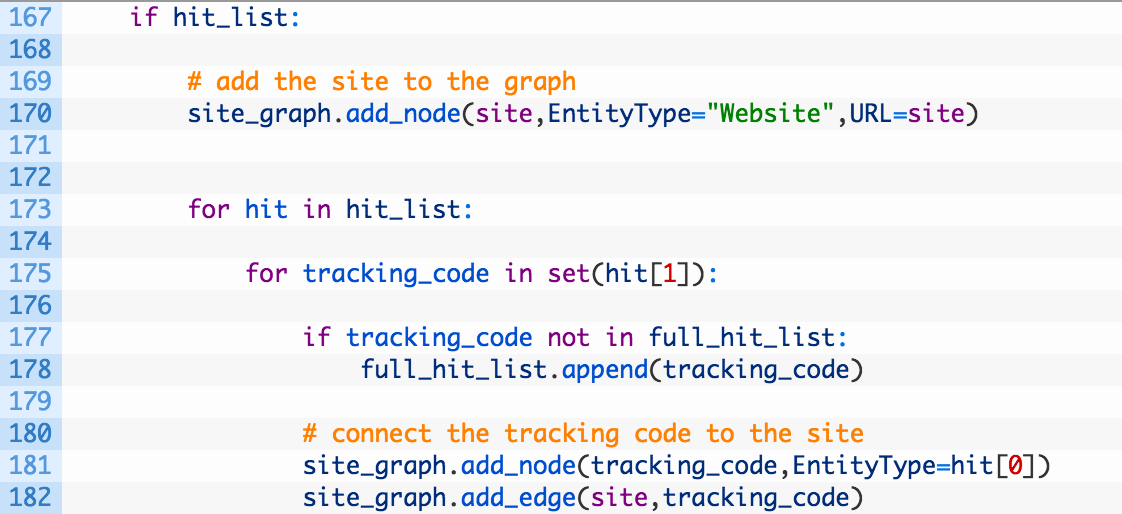
- Line 167-170: if we have valid tracking codes we have detected (167) then we add the website to our NetworkX graph and tag it with the node attribute Website (170).
- Lines 173-178: we iterate over the list of hits (173) which is stored in the following format:
hit_list = [ NETWORK, [ LIST OF TRACKING CODES ] ]
So hit[0] is the network (Google Analytics) and the hit[1] is a list of tracking codes detected on the site that fits that network. We iterate over this list (175) and if the tracking code is not already in our main list of hits we add it (178).
- Lines 181-182: here we are adding the tracking code to the graph, tagging it with it’s network name (181) and then we generate an edge (a line) between the target site and this tracking code (182). This will highlight the relationship between the site and the tracking code, but also by doing this repeatedly will highlight the link between a single tracking code and multiple websites.
Let’s continue adding code. We’re nearly there!
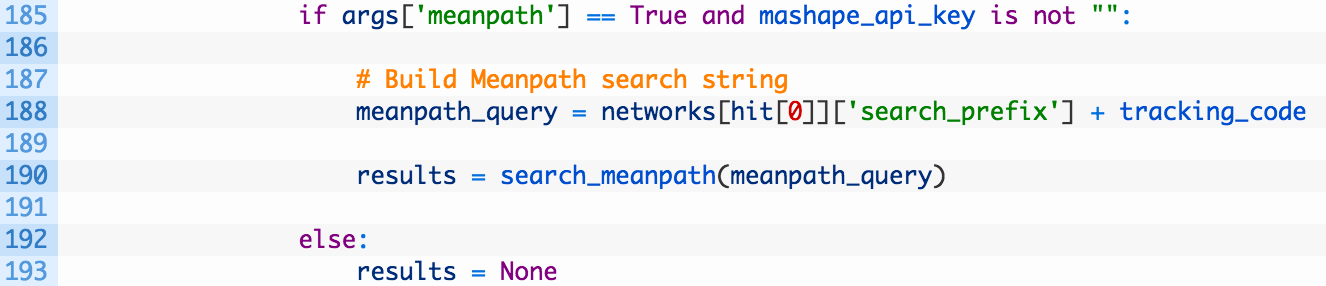
- Line 185: if we have passed in the -mp commandline argument and our Mashape API key is set properly we know we want to perform a Meanpath API search.
- Lines 188-190: we construct our meanpath_query variable using the search prefix for the particular network we are targeting (Google Analytics for example) and then the tracking code that we have discovered (188). This will give us a search query like UA-12345678 for a Google Analytics account for example. We then pass this off to our search_meanpath function (190).
So that little chunk of code is responsible for handling our Meanpath queries, now let’s deal with handling the results of this query.

- Lines 195-197: if we receive valid results back from our Meanpath query (195) we then begin iterating over the results (197).
- Line 200: the result dictionary stores the domain in its _id key. So we are checking if the domain is already in our site_list (this means we already know about this domain) and then we check whether we have a previous Meanpath result (in the form of a [domain,tracking_code]) stored in the list meaning that we have already detected this domain using Meanpath and we should ignore it.
- Lines 203-204: if this is a new target website we print it out (204) and then add the domain paired with the tracking code to our list of sites to process (205).
Whew! Let’s now print out some friendly stats about the information our script processed and generate our graph for Gephi.
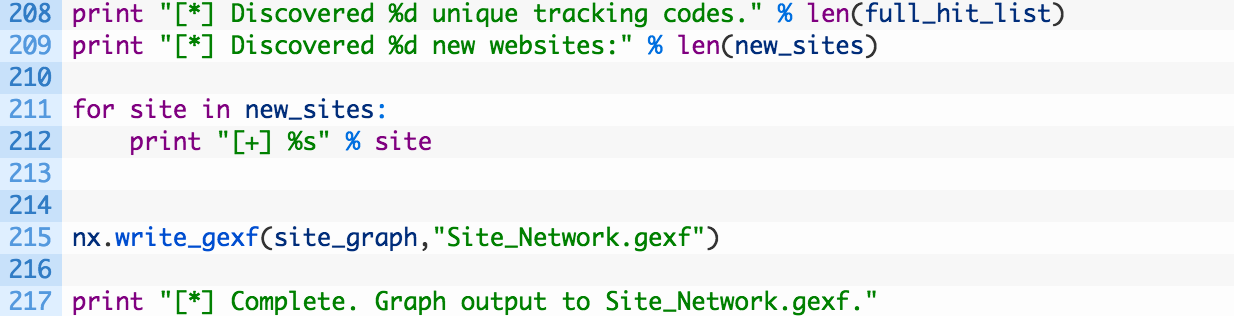
- Lines 208-209: we print out the number of tracking codes we detected (208) and the total number of new sites we found (209).
- Lines 211-212: we iterate over the list of new sites (211) and print out a message (212). This is so you can easily go browse some of your new targets to see what their content looks like.
- Line 215: here we are instructing NetworkX to output a graph for us that will visualize all of this glorious data.
We’re done! Let’s take this thing for a spin.
Let it Rip
So let’s take a look at one of Lawrence’s graphs that he generated in hisarticle. I am going to randomly pick one of the domains syrianinform.com.

So I add my Mashape API key to the script and run the script like so:
~#: python tracking_codes.py -d syriainform.com -mp
[*] Trying http://syriainform.com/… Success! Parsing HTML
[*] Discovered potential new target: material-evidence.com
[*] Discovered potential new target: syriaunion.com
[*] Discovered potential new target: uatoday.biz
[*] Discovered potential new target: digital-diplomacy.fr
[*] Discovered potential new target: e-diplomatie.com
… CUT FOR BREVITY
[*] Trying http://material-evidence.com/… Success! Parsing HTML
[*] Discovered potential new target: material-evidence.com
[*] Trying http://syriaunion.com/… Success! Parsing HTML
[*] Trying http://uatoday.biz/… Success! Parsing HTML
[*] Trying http://digital-diplomacy.fr/… Success! Parsing HTML
… CUT FOR BREVITY
[*] Discovered 2 unique tracking codes.
[*] Discovered 4 new websites:
[+] material-evidence.com
[+] syriaunion.com
[+] uatoday.biz
[+] material-evidence.com
[*] Complete. Graph output to Site_Network.gexf.
Nice! So we discovered a couple of tracking codes and added 4 new websites to our potential target list. Now keep in mind this is not a recursive crawl, so you want to examine the graph and potentially build up a list of domains that you want to additionally analyze or modify the script to continually add to a site list file. You could also disable the script’s double-checking of codes from Meanpath. Be warned if you do this, your crawler could effectively endlessly crawl the Internet if it continues to encounter sites with affiliate tracking codes!
NOTE: This is pretty cool, one of the potential targets uncovered is http://www.diplomatie-digitale.com/ which doesn’t contain the actual tracking code we are after, however, they are discussing how awesome Lawrence’s work is and reference the Google Analytics code that he discovered. This proves that a) Lawrence is awesome and b) that our detection code correctly filters out the site as real target.
Now let’s load it up into Gephi and have a look. Here is a quick video on how to do this:
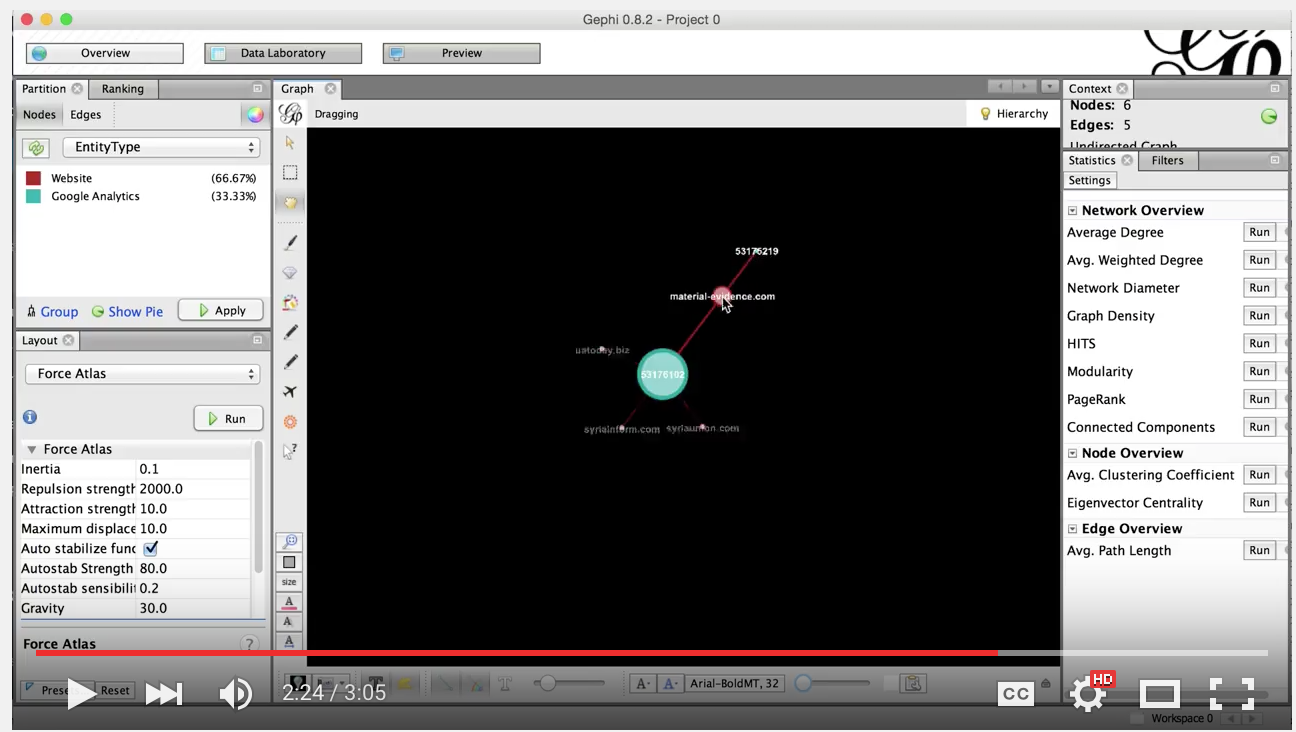
And the resulting graph looks like so:

Beauty! This was an awesome project to collaborate with Lawrence on, and of course there are many uses for this whether you are performing OSINT to write an article or you’re using it for a penetration test.