
Vacuuming Image Metadata from the Wayback Machine
Translations:
This article was originally posted at the AutomatingOSINT.com blog.
Not long ago I was intrigued by the Oct282011.com Internet mystery (if you haven’t heard of it check out this podcast). Friends of the Hunchly mailing list and myself embarked on a brief journey to see if we could root out any additional clues or, of course, solve the mystery. One of the major sources of information for the investigation was The Wayback Machine, which is a popular resource for lots of investigations.
For this particular investigation there were a lot weird images strewn around as clues, and I wondered if it would be possible to retrieve those photos from the Wayback Machine and then examine them for EXIF data to see if we could find authorship details or other tasty nuggets of information. Of course I was not going to do this manually, so I thought it was a perfect opportunity to build out a new tool to do it for me.
We are going to leverage a couple of great tools to make this magic happen. The first is a Python module written by Jeremy Singer-Vine called waybackpack. While you can use waybackpack on the commandline as a standalone tool, in this blog post we are going to simply import it and leverage pieces of it to interact with the Wayback Machine. The second tool is ExifTool, by Phil Harvey. This little beauty is the gold standard when it comes to extracting EXIF information from photos and is trusted the world over.
The goal is for us to pull down all images for a particular URL on the Wayback Machine, extract any EXIF data and then output all of the information into a spreadsheet that we can then go and review.
Let’s get rocking.
Prerequisites
This post involves a few moving parts, so let’s get this boring stuff out of the way first.
Installing Exiftool
On Ubuntu based Linux you can do the following:
# sudo apt-get install exiftool
Mac OSX users can use Phil’s installer here.
For you folks on Windows you will have to do the following:
- Download the ExifTool binary from here. Save it to your C:\Python27 directory (you DO have Python installed right?)
- Rename it to exiftool.exe
- Make sure that C:\Python27 is in your Path. Don’t know how to do this? Google will help. Or just email me.
Installing The Necessary Python Libraries
Now we are ready to install the various Python libraries that we need:
pip install bs4 requests pandas pyexifinfo waybackpack
Alright let’s get down to it shall we?
Coding It Up
Now crack open a new Python file, call it waybackimages.py (download the source here) and start pounding out (use both hands) the following:

Nothing too surprising here. We are just importing all of the required modules, we set our target URL and then create a directory for all of our images to be stored.
Let’s now implement the first function that will be responsible for querying the Wayback Machine for all unique snapshots of our target URL:
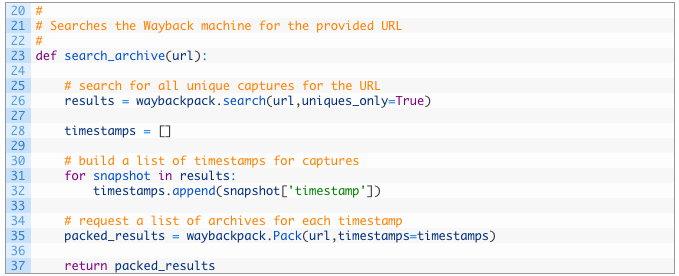
- Line 24: we define our search_archive function to take the url parameter which represents the URL that we want to search the Wayback Machine for.
- Line 27: we leverage the search function provided by waybackpack to search for our URL and also we specify that we only want unique captures so that we aren’t having to examine a bunch of duplicate captures.
- Lines 29-33: we create an empty list of timestamps (29) and then begin walking through the results of our search (32) and add the timestamp that corresponds to a particular capture in the Wayback Machine (33).
- Lines 36-38: we pass in the original URL and the list of timestamps to create a Pack object (36). A Pack object assembles the timestamps and the URL into a Wayback Machine friendly format. We then return this object from our function (38).
Now that our search function is implemented, we need to process the results, retrieve each captured page and then extract all image paths stored in the HTML. Let’s do this now.

- Line 43: we setup our get_image_paths function to receive the Pack object.
- Lines 48-56: we walk through the list of assets (48), and then use the get_archive_url function (51) to hand us a useable URL. We print out a little helper message (53) and then we retrieve the HTML using the fetch function (56).
- Lines 59-60: now that we have the HTML we hand it off to BeautifulSoup (59) so that we can begin parsing the HTML for image tags. The parsing is handled by using the findAll function (60) and passing in the img tag. This will produce a list of all IMG tags discovered in the HTML.
- Lines 63-70: we walk over the list of IMG tags found (64) and we build URLs (67-70) to the images that we can use later to retrieve the images themselves.
- Lines 72-74: if we don’t already have the image URL (72) we print out a message (73) and then add the image URL to our list of all images found (74).
Alright! Now that we have extracted all of the image URLs that we can, we need to download them and process them for EXIF data. Let’s implement this now.
Let’s pick this code apart a little bit:
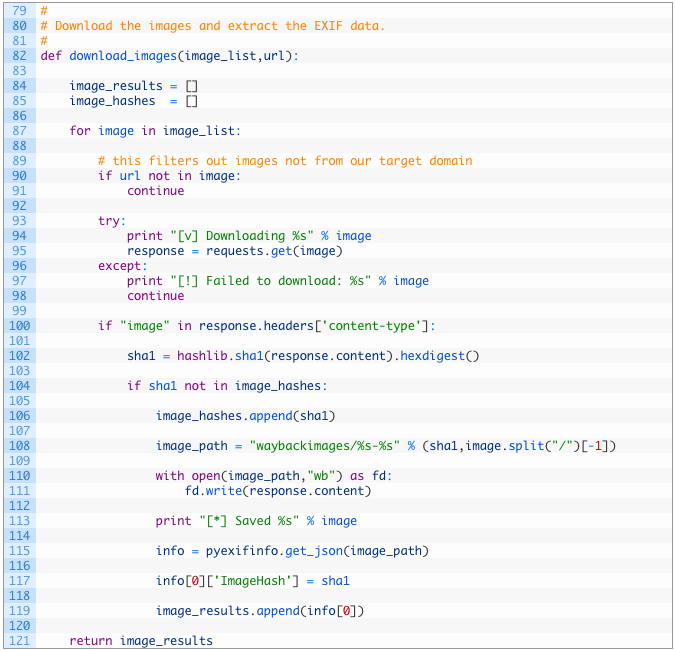
- Line 83: we define our download_images function that takes in our big list of image URLs and the original URL we are interested in.
- Lines 85-86: we create our image_results variable (85) to hold all of our EXIF data results and the image_hashes variable (86) to keep track of all of the unique hashes for the images we download. More on this shortly.
- Lines 88-98: we walk through the list of image URLs (88) and if our base URL is not in the image path (91) then we ignore it. We then download the image (96) so that we can perform our analysis.
- Lines 101-103: if we have successfully downloaded the image (101), we then SHA-1 hash the image so that we can track unique images. This allows us to have multiple images at with the same file name but if the contents of the image are different (even by one byte) then we will track them separately. This also prevents us from having multiple copies of exact duplicate images.
- Lines 105-114: if it is a new unique image (105) we add the hash to our list of image hashes (107) and then we write the image out to disk (111).
- Line 116: here we are calling the pyexifinfo function get_json. This function extracts the EXIF data and then returns the results as a Python dictionary.
- Lines 118-120: we add our own key to the info dictionary that contains the SHA-1 hash of the image (118) and then we add the dictionary to our master list of results (120).
We are almost finished. Now we just need to tie all of these functions together and get some output in CSV format so that we can easily review all of the EXIF data that we have discovered. Time to put the finishing touches on this script!
Let’s break down this last bit of code:
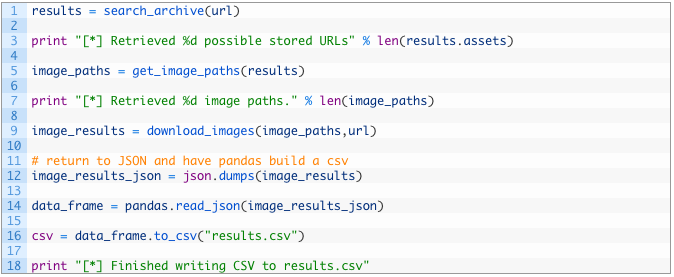
- Lines 124-132: we call all of our functions starting by performing the Wayback Machine search (124), extracting the image paths (128) and then downloading and processing all of the images (132).
- Lines 135-139: we convert the returned dictionary to a JSON string (135), and then pass that JSON into the pandas read_json function (137) that will create a dataframe in pandas. We then leverage a wonderful function to_csv that converts that data frame to a CSV file, complete with automatic headers. This saves us from having to code up a complicated CSV creation routine. The CSV file is stored in results.csv in the same directory as the script.
Let It Rip!
Ok now for the fun part. Set the URL you are interested in, and just run the script from the command line or from your favourite Python IDE. You should see some output like the following:
[*] Retrieved 41 possible stored URLs
[*] Retrieving https://web.archive.org/web/20110823161411/http://www.oct282011.com/ (1 of 41)
[*] Retrieving https://web.archive.org/web/20110830211214/http://www.oct282011.com/ (2 of 41)
[+] Adding new image: https://web.archive.org/web/20110830211214/http://www.oct282011.com/st.jpg
…
[*] Saved https://web.archive.org/web/20111016032412/http://www.oct282011.com/material_same_habits.png
[v] Downloading https://web.archive.org/web/20111018162204/http://www.oct282011.com/ignoring.png
[v] Downloading https://web.archive.org/web/20111018162204/http://www.oct282011.com/material_same_habits.png
[v] Downloading https://web.archive.org/web/20111023153511/http://www.oct282011.com/ignoring.png
[v] Downloading https://web.archive.org/web/20111023153511/http://www.oct282011.com/material_same_habits.png
[v] Downloading https://web.archive.org/web/20111024101059/http://www.oct282011.com/ignoring.png
[v] Downloading https://web.archive.org/web/20111024101059/http://www.oct282011.com/material_same_habits.png
[*] Finished writing CSV to results.csv
