Automating Photo Retrieval for Geolocating - Part 2:Wikimapia
Translations:

This was originally posted to AutomatingOSINT.com.
Welcome back! To continue our photo retrieval magic, we are going to now incorporate Wikimapia photos. If you remember our first posts on Panoramio, the goal is to automate as much photo retrieval as we can in order to speed up the process of geolocating photographs. Much like Panoramio, Wikimapia allows people to upload photographs of local scenery and buildings which can be extremely useful for geolocating a video or photograph. As well there is curated content inside of Wikimapia that can help users understand what the local buildings actually are. I am going to teach you a few new techniques including the basics of parsing HTML.
Wikimapia API – Creating Keys
The Wikimapia API requires you to register with the site and to setup a key. The steps are pretty straightforward:
- Head over to here to register with Wikimapia.
- Once you’ve done that, head to the key creation page here.
- When you are filling out the form ensure you set the drop-down box to “Application”, and then just punch in a vague description for the name and platform entries.
- Once you have created a key you can retrieve it from the My Keys page.
Great! Now let’s take a look at the Wikimapia API itself.
Wikimapia API – Searching
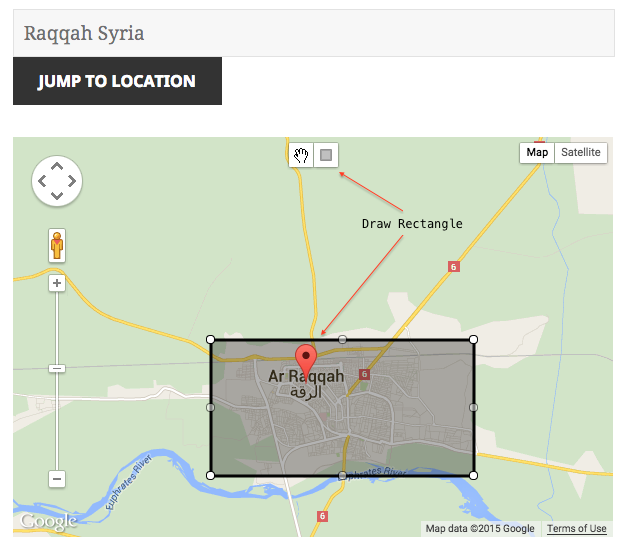
There are a number of API calls that you can make to Wikimapia, but the one we are interested in is the Place.Search call. The Wikimapia API is called by making HTTP GET requests (this should sound familiar from our Panoramio post) and then we parse the JSON response (also should sound familiar). In our previous post we had to use a bounding box to provide a geofence for our photo search, but Wikimapia takes a center point and a radius in meters to search around. I have updated the bounding box tool to show the radius (measured between the center and the northeast corner of the box) and the center point of the bounding box. We could write some Python code to do these calculations, but I can leave that to you as a homework assignment.
First we need to install a wonderful HTML parsing library called Beautiful Soup. I will dig into this library more in depth in a future post but for now let’s just do the usual:
C:\Users\Justin> pip install beautifulsoup4
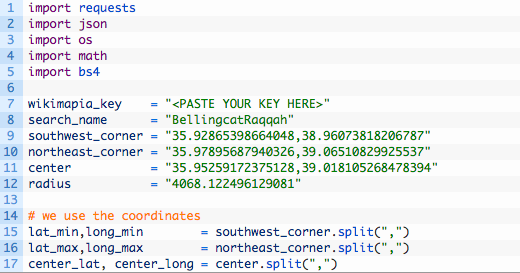
Now let’s open up auto_image_search_extended.py (you can download from here to follow along) and enter the following code:
Ok let’s take a look at the new pieces of code that we added:
- Line 5: here we are importing the Beautiful Soup library for HTML parsing.
- Line 7: the wikimapia_key variable will hold our Wikimapia key, just copy and paste it from your Wikimapia account.
- Lines 11 – 12: these are our new variables to hold the center of our bounding box and the search radius that is required for the Wikimapia API.
- Line 17: we are just splitting the center point into a latitude / longitude pair.
Alright nothing too heavy quite yet, this is just the typical setup code and creating some variables. Now let’s begin putting in the plumbing for talking to Wikimapia.
Polling the Wikimapia API
If you remember our previous post on Panoramio, it will come as no surprise that we have to poll the Wikipmapia API for “pages” of results. Wikimapia allows you to retrieve up to 100 records per “page”. This means that we have to create much the same logic as our previous script where we are going to look for the total number of results, and then continually increase the page count until we have retrieved all of the search results. This is no different than you clicking on the “Next” button when looking at Google search results. Let’s implement these functions now:

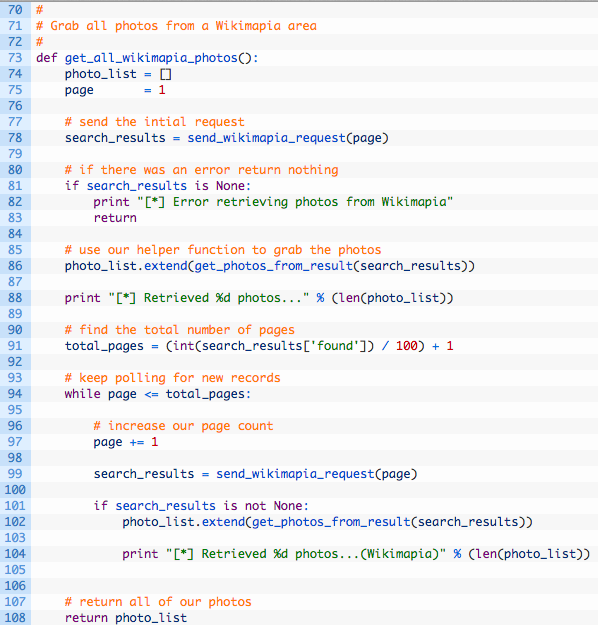
This function should look a bit familiar, as it is very close to the Panoramio version. We are just building up a URL that has all of the search parameters required to talk to the Wikimapia API, and then sending an HTTP GET request to retrieve the search results as a JSON document. We parse that JSON document, and return the Python dictionary back to our polling function. Let’s implement that polling function now:
This also should not look too surprising. Let’s just look at the relevant pieces of code that are different from our Panoramio search script:
- Line 75: here is our page variable that tells the Wikimapia API which set of results we are looking to retrieve.
- Line 86: here we are using a helper function get_photos_from_result (we will implement shortly) to retrieve the photos from the Wikimapia results.
- Line 91: here we are calculating the total number of pages by dividing by the page size (100) and then we add an extra page for any leftovers.
- Line 94: this loop continues to execute while our page count is less than the total number of pages calculated.
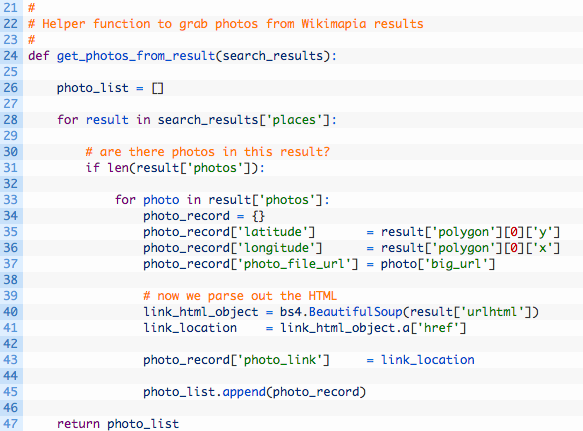
Ok, as mentioned before, we have created a small helper function that will extract the photos from the Wikimapia API results. When you perform a search you will get all kinds of results back including tagged locations, comments, etc. We only want the photos out of all of those results, so our helper function will help to deal with that. Wikimapia also returns an HTML URL that points to the actual photo and it’s associated user marker for that photo. This typically has great context information about the photo, so we want to extract this URL as well so that we can use it. Let’s this function now just below all of our variables and setup code.
NOTE: The Wikimapia API documents a data_blocks parameter that is designed to only return results that, for example, contain photos. I could not make this work, let me know if you figure out why that is.
Ok let’s break this code down a bit.
- Lines 28 and 30: as we loop through the results if we detect that there are photos for a search result we begin to extract the details of the search result.
- Lines 34 – 37: we are building a Python dictionary that contains the latitude, longitude and a URL to the image so we can load it in our HTML file.
- Line 40: here we are passing in the HTML URL from Wikimapia to the Beautiful Soup module. It creates a Python object that we can use to then extract the URL from the HTML.
- Line 41: here we are actually extracting the URL itself.
I am going to explain a bit more on the HTML extraction bit. An example Wikimapia URL that is returned is:
<a class="wikimapia-link" href="http://wikimapia.org/10651335/Dalla-roundabout">Dalla roundabout?</a>
We are only interested in the href value as we want to make the photo clickable in our own HTML file. So you can see how using Beautiful Soup we are able to select the href attribute directly and extract it out for our own use.
Wrapping it Up
Ok all that is left for us to do is update our HTML logging function and then make our Wikimapia function calls. Let’s see how to do this:

So let’s look at the major changes we have made here:
- Lines 187-196: we are modifying our old logging function to take into account that we might have a special URL as is the case with the Wikimapia API. If we have a URL we use it, if not then we use the default case of creating a Google Maps link.
- Lines 204-214: here we are just setting up the necessary function calls, and building a large list of images that are compiled from both Wikimapia and Panoramio.
Run It!
If you run the script like the previous scripts (don’t forget your Wikimapia key) then you should see some output like the following:
C:\Users\Justin\Desktop> python auto_image_search_extended.py [*] Retrieved 3 photos... [*] Retrieved 6 photos...(Wikimapia) [*] Retrieved 13 photos...(Wikimapia) [*] Retrieved 14 photos...(Wikimapia) [*] Retrieved 14 photos...(Wikimapia) [*] Retrieved 14 photos...(Wikimapia) [*] Retrieved 50 photos... [*] Retrieved 100 photos...(Panoramio) [*] Retrieved 150 photos...(Panoramio) [*] Retrieved 200 photos...(Panoramio) [*] Retrieved 210 photos...(Panoramio) [**] Total of 224 pictures retrieved.
Just like that we have added an additional 14 pictures to our HTML page than we had previously. You may find even more depending on the location that you are interested in. The Wikimapia results will be first in your HTML file, so try clicking one and see where it takes you. Do you have other image sites that you are interested in getting results from, post in the comments or send me an email.