Automating Photo Retrieval for Geolocating – Part 1 Continued: Panoramio
Translations:
This post originally appeared on AutomatingOSINT.com.
Ok we’re back. After a bit of feedback from readers on the first post and some investigation on my end, we have discovered the following:
- Panoramio API does not report the correct number of results as an API result. So your script might say that it found 200 images but only retrieve 150 for example.
- Using the default image size makes for some scary HTML pages.
- The Pynoramio Python library is not downloading the full set of results. I am not sure why this is.
So I am going to revamp this post to show you how to access the Panoramio API yourself, and introduce you to an amazingly useful Python library.
The Python requests Library
The Python requests library is one of the most useful and most used Python libraries around. It is basically a super simple way to make HTTP requests (HTTP is the protocol your web browser talks, as well as 99% of all API’s) inside your Python scripts. The sad thing is that it is not installed by default with Python. So remembering the previous post, let’s use pip to install it:
C:\Users\Justin> pip install requests
Done! Now we are going to use requests to directly access the Panoramio API ourselves.
Talking to The Panoramio API
The Panoramio Data API is documented here and from our previous foray into using it, we do have some basics on how the information is going to be formatted in order to get results back. The trick now is that we are going to be directly hitting their API and having to actually deal with the raw data before being able to generate our HTML page. Let’s waste no time and start coding, open a new Python script called auto_image_search_extended.py and punch in the following code (you can download the script here):
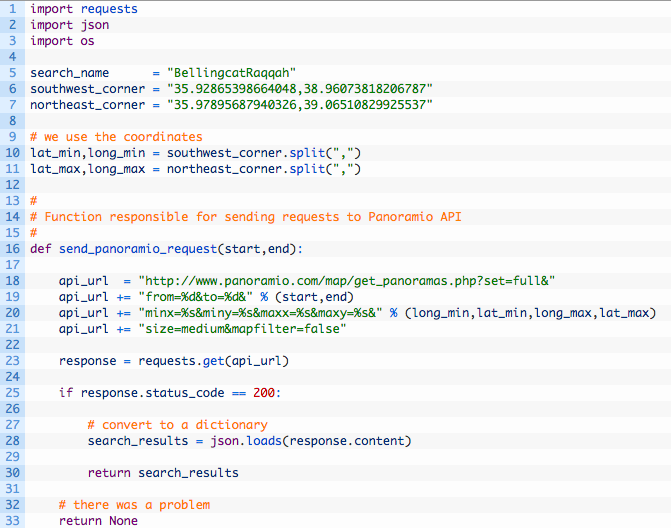
Let’s have a look at what the code is doing here:
- Lines 5-11: these should look familiar from the first post. These are just the basic parameters for our search.
- Line 16: we define our send_panoramio_request function which is going to be responsible for talking to the Panoramio API.
- Lines 18-21: here we are setting up the Panoramio API URL with all of the parameters as discussed in their documentation. The start and end parameters are so we can request “pages” of results. For example the first page would be images 1 through 50. The second page would be images 51 through 100.
- Line 23: this is the magic right here. The requests.get method does an HTTP GET on the URL that we have specified. The Panoramio API returns a JSON document that we can then parse.
- Lines 25-30: if we have a successful HTTP request (200 indicates success) then we hand off the raw JSON document to the json library and have it convert the JSON to a Python dictionary.
Paging Results
Now that we have the first cut of talking to the Panoramio API we need to be able to continually poll it for results. Once we have made the request and converted the JSON to a Python dictionary, we have the following keys:
search_results[‘count’] – the number of search results (ignore it, it lies like a rug).
search_results[‘map_location’] – the Panoramio map location.
search_results[‘has_more’] – whether there are more search results to retrieve.
search_results[‘photos’] – a list of all photos that are part of our search results.
The trick is in the has_more key. We can continually ask for results by paging through them until the has_more value is set to False. Let’s implement this in code:
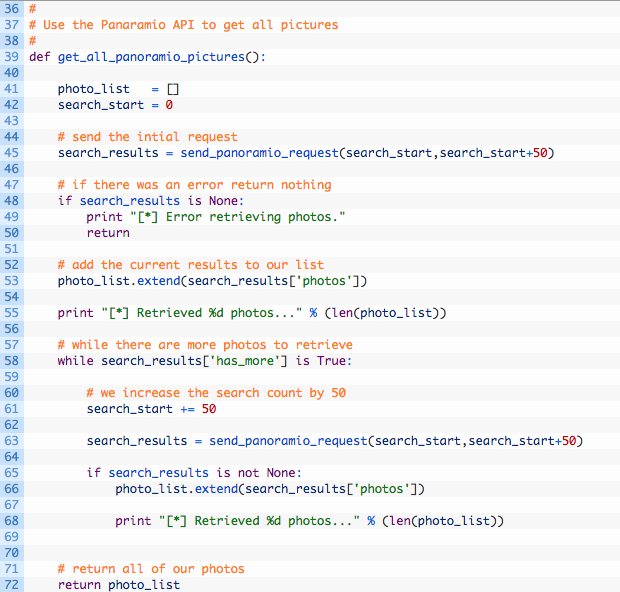
Let’s break this code down a bit:
- Line 39: we define our get_all_panoramio_pictures function.
- Lines 41-42: here we setup our photo list, and set our paging variable to zero.
- Line 45: we send off our first request with the paging set to zero and to 50. This will return the first 50 results from the API.
- Line 53: if the request was successful we add the returned photos to our photo list.
- Lines 58-68: this is a loop. This chunk of code will continue executing as long as the has_more key is set to True. Inside the loop we just keep increasing our page variable by 50 and requesting the next 50 photos in the search results. Once we have retrieved all the photos we return the photo list.
Easy peasy, and you have learned some key programming concepts along the way! We are nearly there so let’s start to put the finishing touches on the script.
Logging to the HTML File
Just like our last script we are going to log to an HTML file. This time around we are going to do it a little differently in that we are just going to pass in the list of photos and have the logging function add each one to the HTML file. Add the following lines of code to your script:
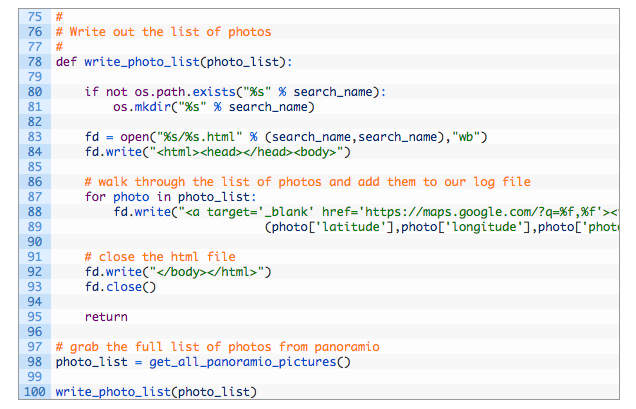
This is pretty straightforward code, and is much the same as the first script we wrote. The tail end of the script is just calling the functions that we previously setup. Now you can do much the same as in our previous case, use my bounding box tool to get the coordinates you want and run your query. In my example case you should get a new folder called “BellingcatRaqqah” with an HTML file inside that you can open and hunt for photos to help you geolocate videos and other photography.
Wrapping Up
You have learned some extremely useful techniques in this post. The main one being that we can write our own code to interact with an API without relying on how someone else has implemented it. This breaks you free of having to use other people’s tooling, and makes you more flexible as an OSINT practitioner in the future. There is nothing more frustrating than relying on a particular tool or set of libraries only to have it get shutdown or become out of date. As mentioned previously, we are going to tackle Wikimapia next, and include Wikimapia photos in our HTML page.