
Guide To Using Reverse Image Search For Investigations
Reverse image search is one of the most well-known and easiest digital investigative techniques, with two-click functionality of choosing “Search Google for image” in many web browsers. This method has also seen widespread use in popular culture, perhaps most notably in the MTV show Catfish, which exposes people in online relationships who use stolen photographs on their social media.
However, if you only use Google for reverse image searching, you will be disappointed more often than not. Limiting your search process to uploading a photograph in its original form to just images.google.com may give you useful results for the most obviously stolen or popular images, but for most any sophisticated research project, you need additional sites at your disposal — along with a lot of creativity.
This guide will walk through detailed strategies to use reverse image search in digital investigations, with an eye towards identifying people and locations, along with determining an image’s progeny. After detailing the core differences between the search engines, Yandex, Bing, and Google are tested on five test images showing different objects and from various regions of the world.
Beyond Google
The first and most important piece of advice on this topic cannot be stressed enough: Google reverse image search isn’t very good.
As of this guide’s publication date, the undisputed leader of reverse image search is the Russian site Yandex. After Yandex, the runners-up are Microsoft’s Bing and Google. A fourth service that could also be used in investigations is TinEye, but this site specializes in intellectual property violations and looks for exact duplicates of images.
Yandex
Yandex is by far the best reverse image search engine, with a scary-powerful ability to recognize faces, landscapes, and objects. This Russian site draws heavily upon user-generated content, such as tourist review sites (e.g. FourSquare and TripAdvisor) and social networks (e.g. dating sites), for remarkably accurate results with facial and landscape recognition queries.
Its strengths lie in photographs taken in a European or former-Soviet context. While photographs from North America, Africa, and other places may still return useful results on Yandex, you may find yourself frustrated by scrolling through results mostly from Russia, Ukraine, and eastern Europe rather than the country of your target images.
To use Yandex, go to images.yandex.com, then choose the camera icon on the right.

From there, you can either upload a saved image or type in the URL of one hosted online.

If you get stuck with the Russian user interface, look out for Выберите файл (Choose file), Введите адрес картинки (Enter image address), and Найти (Search). After searching, look out for Похожие картинки (Similar images), and Ещё похожие (More similar).
The facial recognition algorithms used by Yandex are shockingly good. Not only will Yandex look for photographs that look similar to the one that has a face in it, but it will also look for other photographs of the same person (determined through matching facial similarities) with completely different lighting, background colors, and positions. While Google and Bing may just look for other photographs showing a person with similar clothes and general facial features, Yandex will search for those matches, and also other photographs of a facial match. Below, you can see how the three services searched the face of Sergey Dubinsky, a Russian suspect in the downing of MH17. Yandex found numerous photographs of Dubinsky from various sources (only two of the top results had unrelated people), with the result differing from the original image but showing the same person. Google had no luck at all, while Bing had a single result (fifth image, second row) that also showed Dubinsky.

Yandex is, obviously, a Russian service, and there are worries and suspicions of its ties (or potential future ties) to the Kremlin. While we at Bellingcat constantly use Yandex for its search capabilities, you may be a bit more paranoid than us. Use Yandex at your own risk, especially if you are also worried about using VK and other Russian services. If you aren’t particularly paranoid, try searching an un-indexed photograph of yourself or someone you know in Yandex, and see if it can find yourself or your doppelganger online.
Bing
Over the past few years, Bing has caught up to Google in its reverse image search capabilities, but is still limited. Bing’s “Visual Search”, found at images.bing.com, is very easy to use, and offers a few interesting features not found elsewhere.
Within an image search, Bing allows you to crop a photograph (button below the source image) to focus on a specific element in said photograph, as seen below. The results with the cropped image will exclude the extraneous elements, focusing on the user-defined box. However, if the selected portion of the image is small, it is worth it to manually crop the photograph yourself and increase the resolution — low-resolution images (below 200×200) bring back poor results.
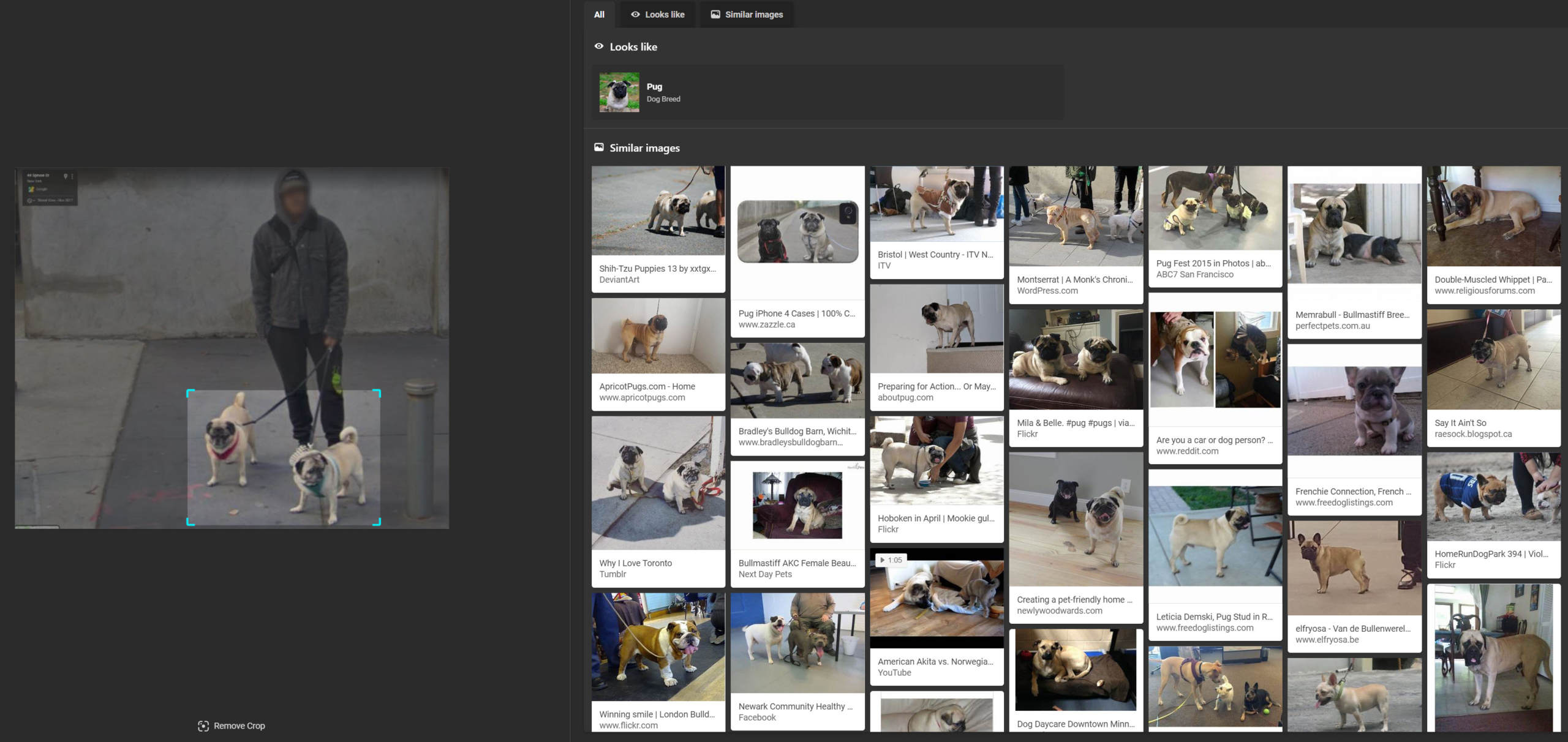
Below, a Google Street View image of a man walking a couple of pugs was cropped to focus on just the pooches, leading to Bing to suggest the breed of dog visible in the photograph (the “Looks like” feature), along with visually similar results. These results mostly included pairs of dogs being walked, matching the source image, but did not always only include pugs, as French bulldogs, English bulldogs, mastiffs, and others are mixed in.
By far the most popular reverse image search engine, at images.google.com, Google is fine for most rudimentary reverse image searches. Some of these relatively simple queries include identifying well-known people in photographs, finding the source of images that have been shared quite a bit online, determining the name and creator of a piece of art, and so on. However, if you want to locate images that are not close to an exact copy of the one you are researching, you may be disappointed.
For example, when searching for the face of a man who tried to attack a BBC journalist at a Trump rally, Google can find the source of the cropped image, but cannot find any additional images of him, or even someone who bears a passing resemblance to him.

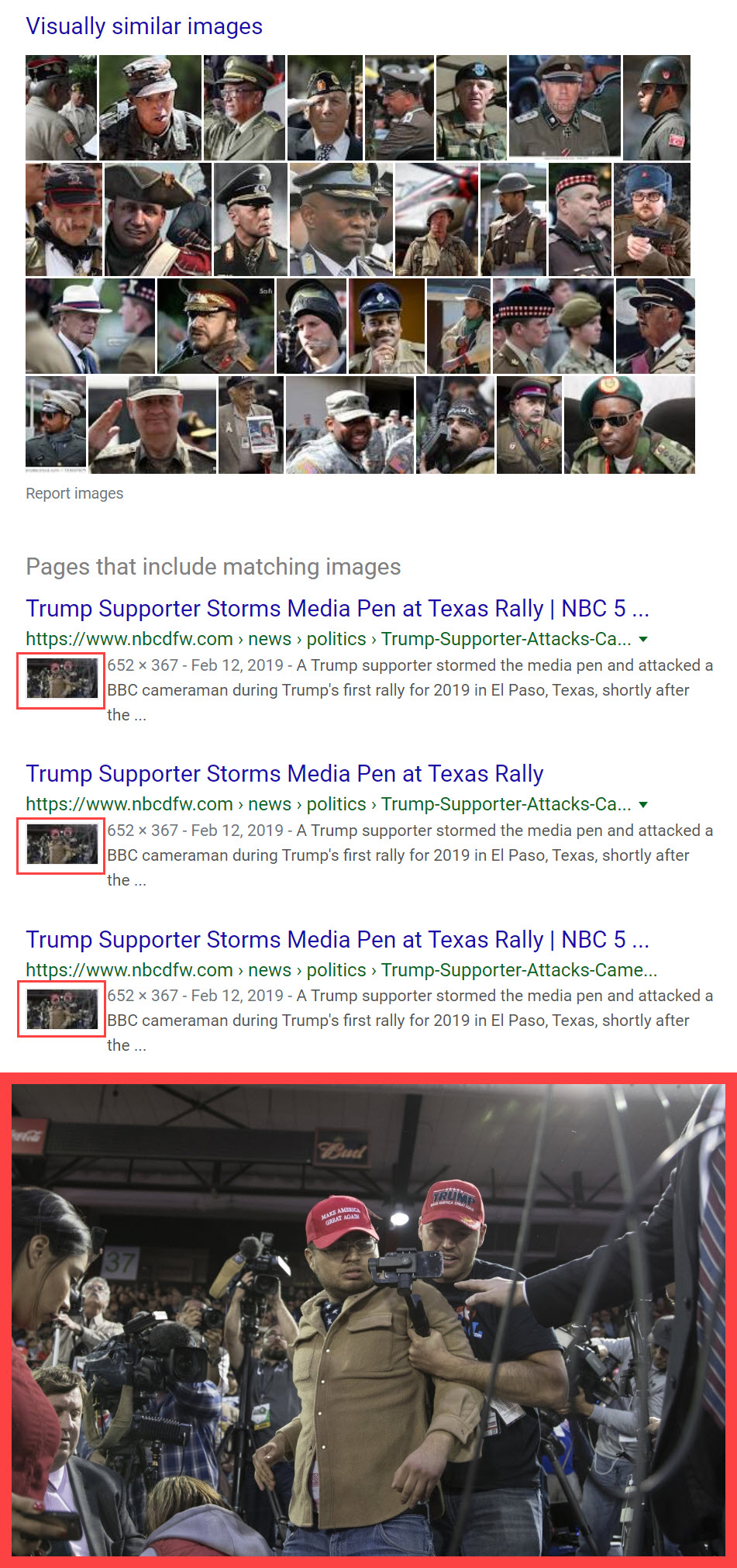
While Google was not very strong in finding other instances of this man’s face or similar-looking people, it still found the original, un-cropped version of the photograph the screenshot was taken from, showing some utility.
Five Test Cases
For testing out different reverse image search techniques and engines, a handful of images representing different types of investigations are used, including both original photographs (not previously uploaded online) and recycled ones. Due to the fact that these photographs are included in this guide, it is likely that these test cases will not work as intended in the future, as search engines will index these photographs and integrate them into their results. Thus, screenshots of the results as they appeared when this guide was being written are included.
These test photographs include a number of different geographic regions to test the strength of search engines for source material in western Europe, eastern Europe, South America, southeast Asia, and the United States. With each of these photographs, I have also highlighted discrete objects within the image to test out the strengths and weaknesses for each search engine.
Feel free to download these photographs (every image in this guide is hyperlinked directly to a JPEG file) and run them through search engines yourself to test out your skills.
Olisov Palace In Nizhny Novgord, Russia (Original, not previously uploaded online)

Isolated: White SUV in Nizhny Novgorod

Isolated: Trailer in Nizhny Novgorod

Cityscape In Cebu, Philippines (Original, not previously uploaded online)

Isolated: Condominium complex, “The Padgett Place“

Isolated: “Waterfront Hotel“

Students From Bloomberg 2020 Ad (Screenshot from video)
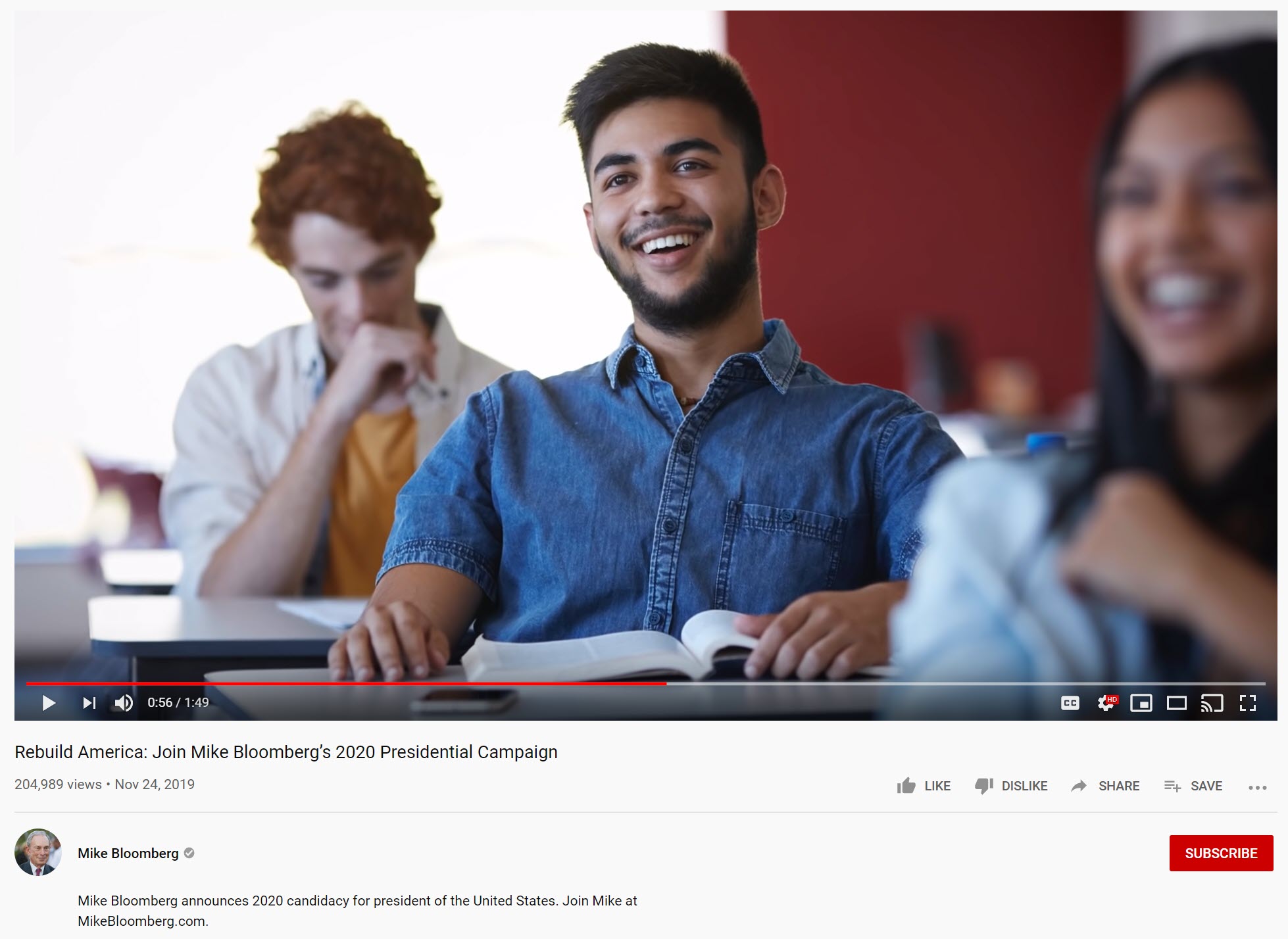
Isolated: Student

Av. do Café In São Paulo, Brazil (Screenshot from Google Street View)

Isolated: Toca do Açaí

Isolated: Estacionamento (Parking)

Amsterdam Canal (Original, not previously uploaded online)

Isolated: Grey Heron

Isolated: Dutch Flag (also rotated 90 degrees clockwise)

Results
Each of these photographs were chosen in order to demonstrate the capabilities and limitations of the three search engines. While Yandex in particular may seem like it is working digital black magic at times, it is far from infallible and can struggle with some types of searches. For some ways to possibly overcome these limitations, I’ve detailed some creative search strategies at the end of this guide.
Novgorod’s Olisov Palace
Predictably, Yandex had no trouble identifying this Russian building. Along with photographs from a similar angle to our source photograph, Yandex also found images from other perspectives, including 90 degrees counter-clockwise (see the first two images in the third row) from the vantage point of the source image.
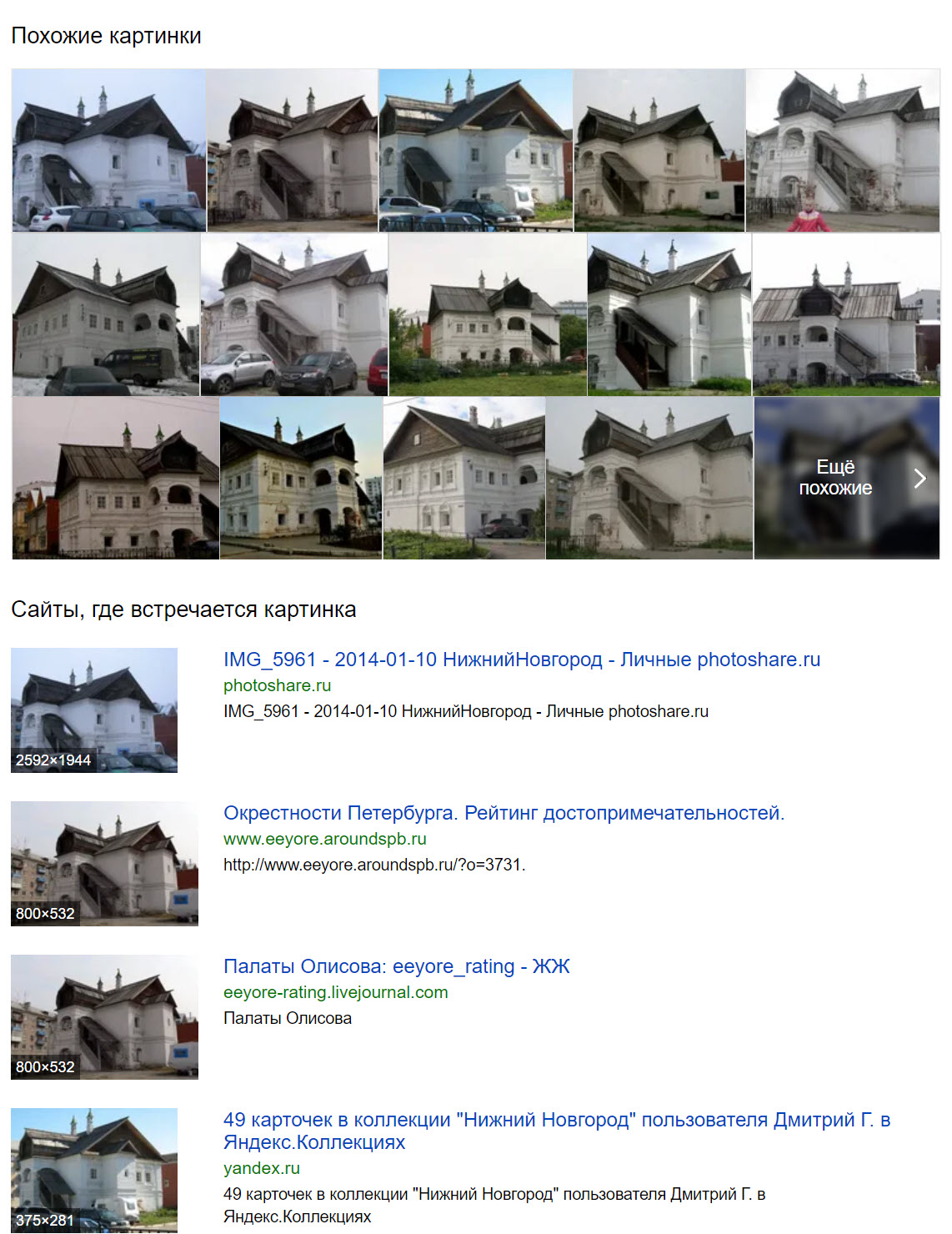
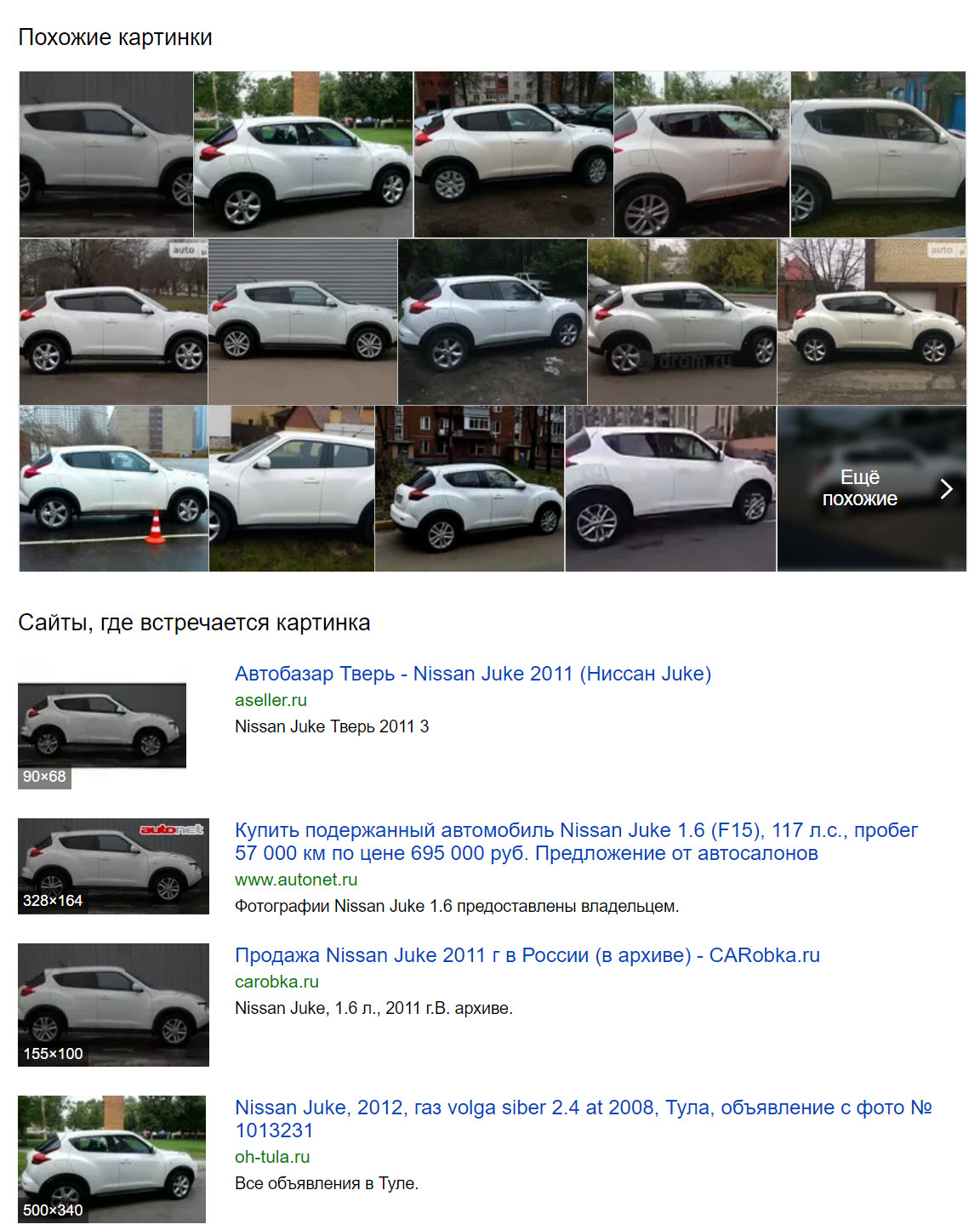
Yandex also had no trouble identifying the white SUV in the foreground of the photograph as a Nissan Juke.
Lastly, in the most challenging isolated search for this image, Yandex was unsuccessful in identifying the non-descript grey trailer in front of the building. A number of the results look like the one from the source image, but none are an actual match.

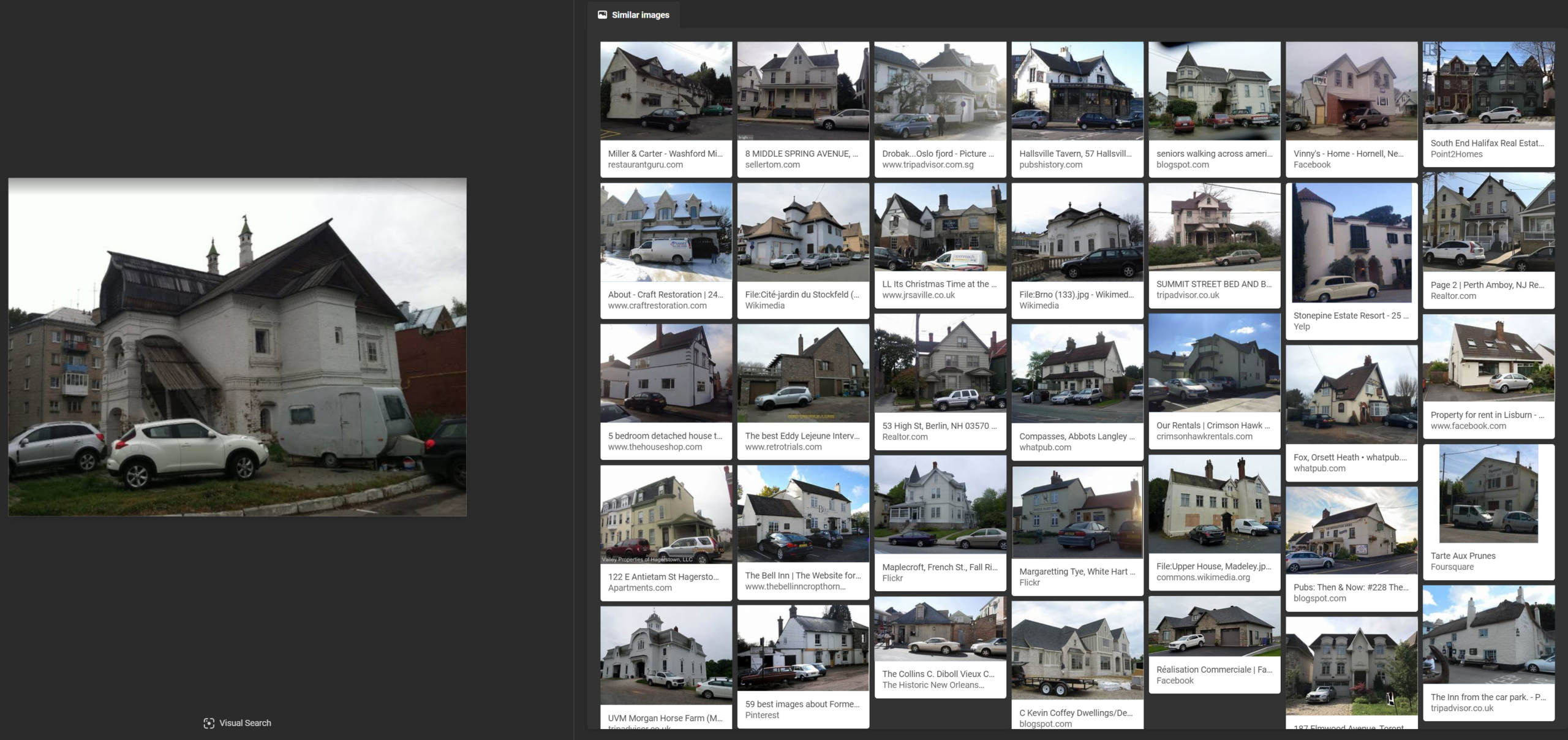
Bing had no success in identifying this structure. Nearly all of its results were from the United States and western Europe, showing houses with white/grey masonry or siding and brown roofs.
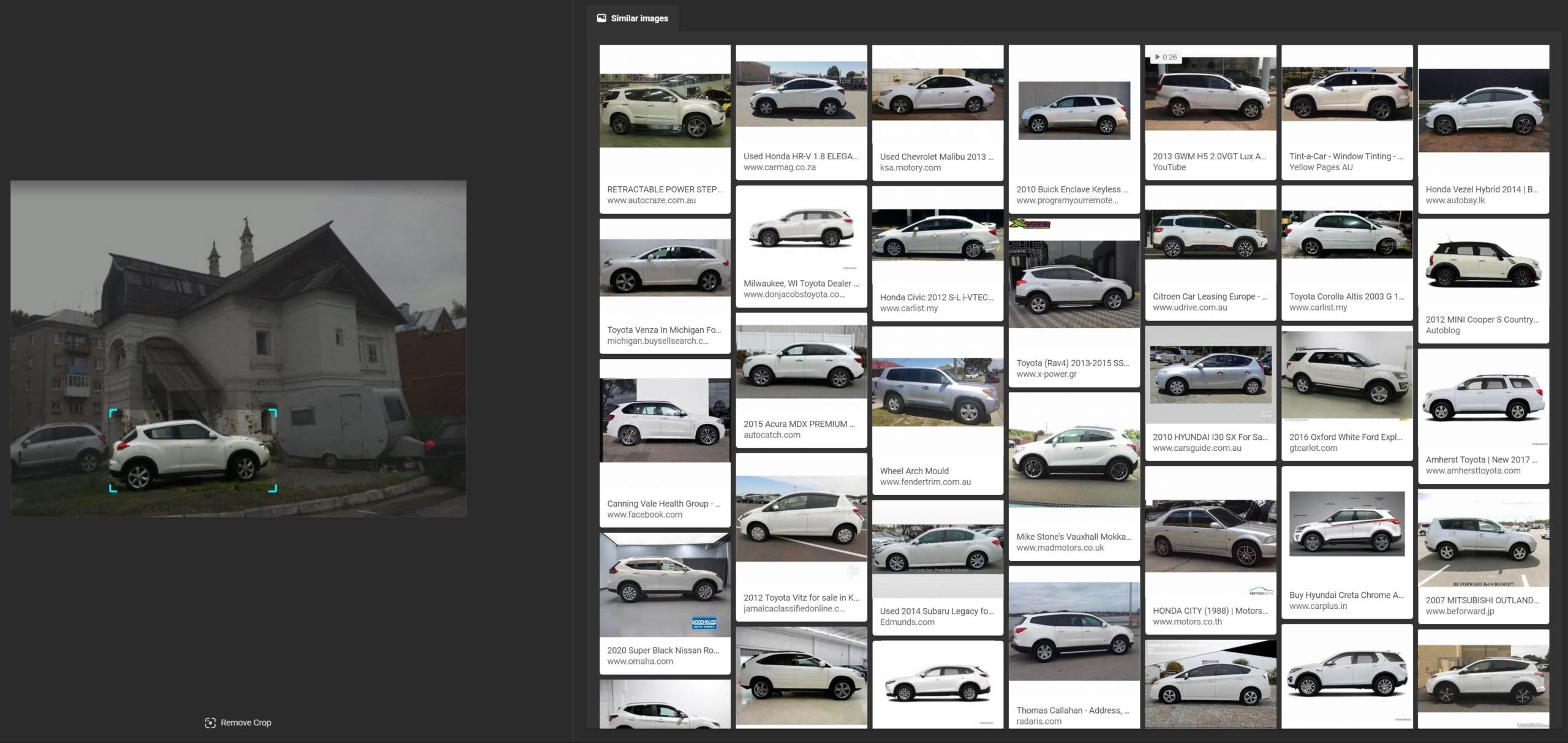
Likewise, Bing could not determine that the white SUV was a Nissan Juke, instead focusing on an array of other white SUVs and cars.
Lastly, Bing failed in identifying the grey trailer, focusing more on RVs and larger, grey campers.
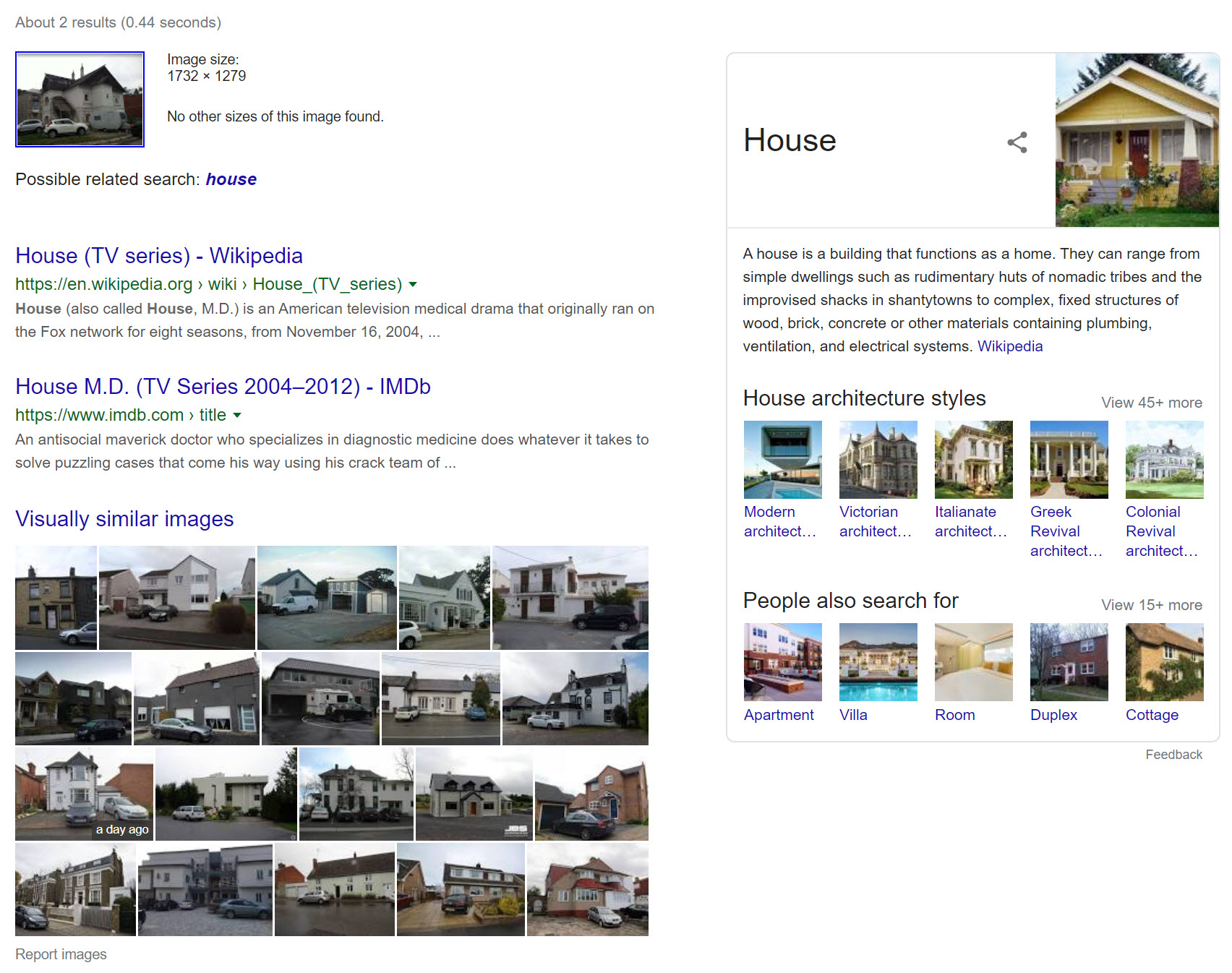
Google‘s results for the full photograph are comically bad, looking to the House television show and images with very little visual similarity.
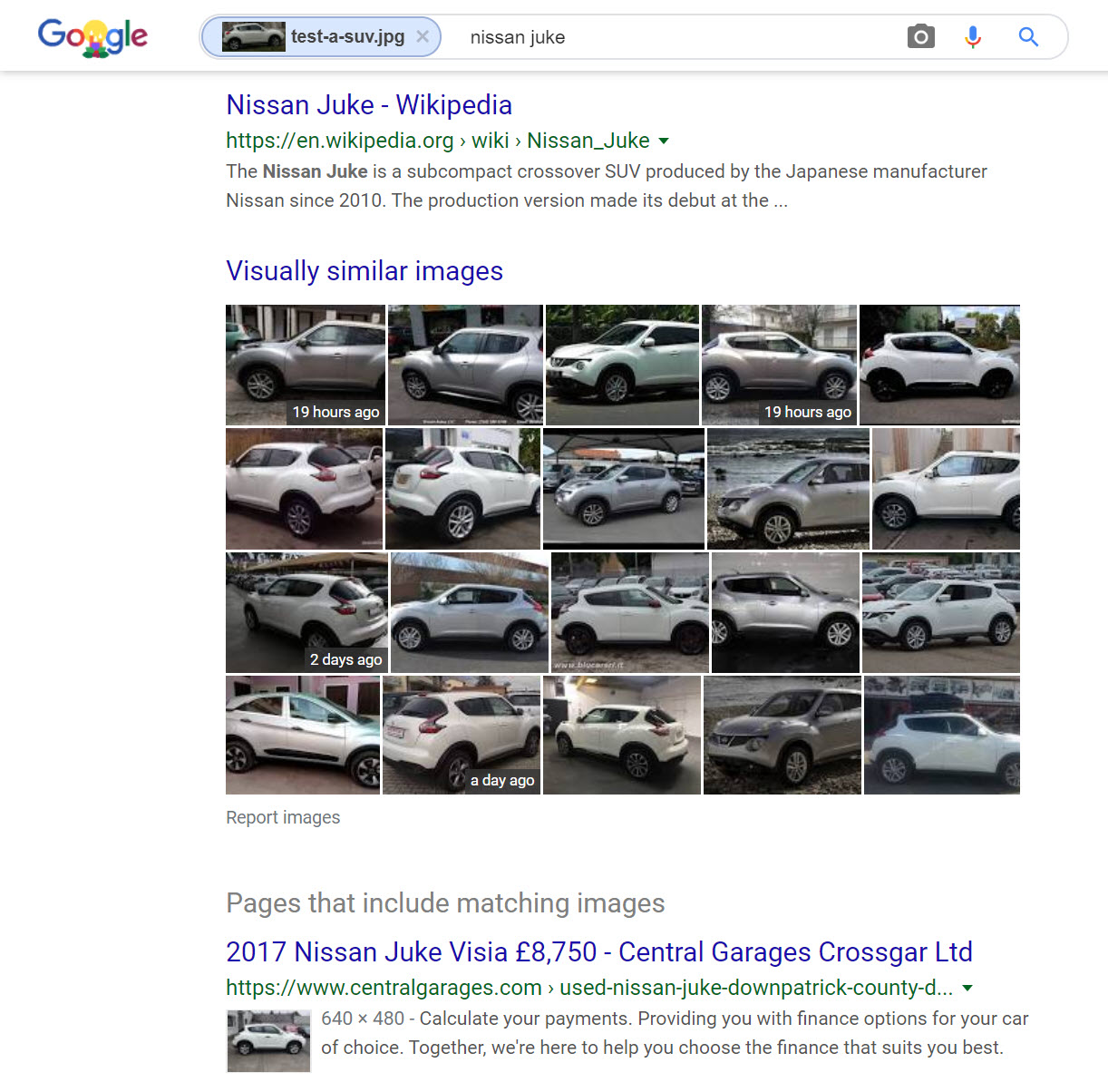
Google successfully identified the white SUV as a Nissan Juke, even noting it in the text field search. As seen with Yandex, feeding the search engine an image from a similar perspective as popular reference materials — a side view of a car that resembles that of most advertisements — will best allow reverse image algorithms to work their magic.
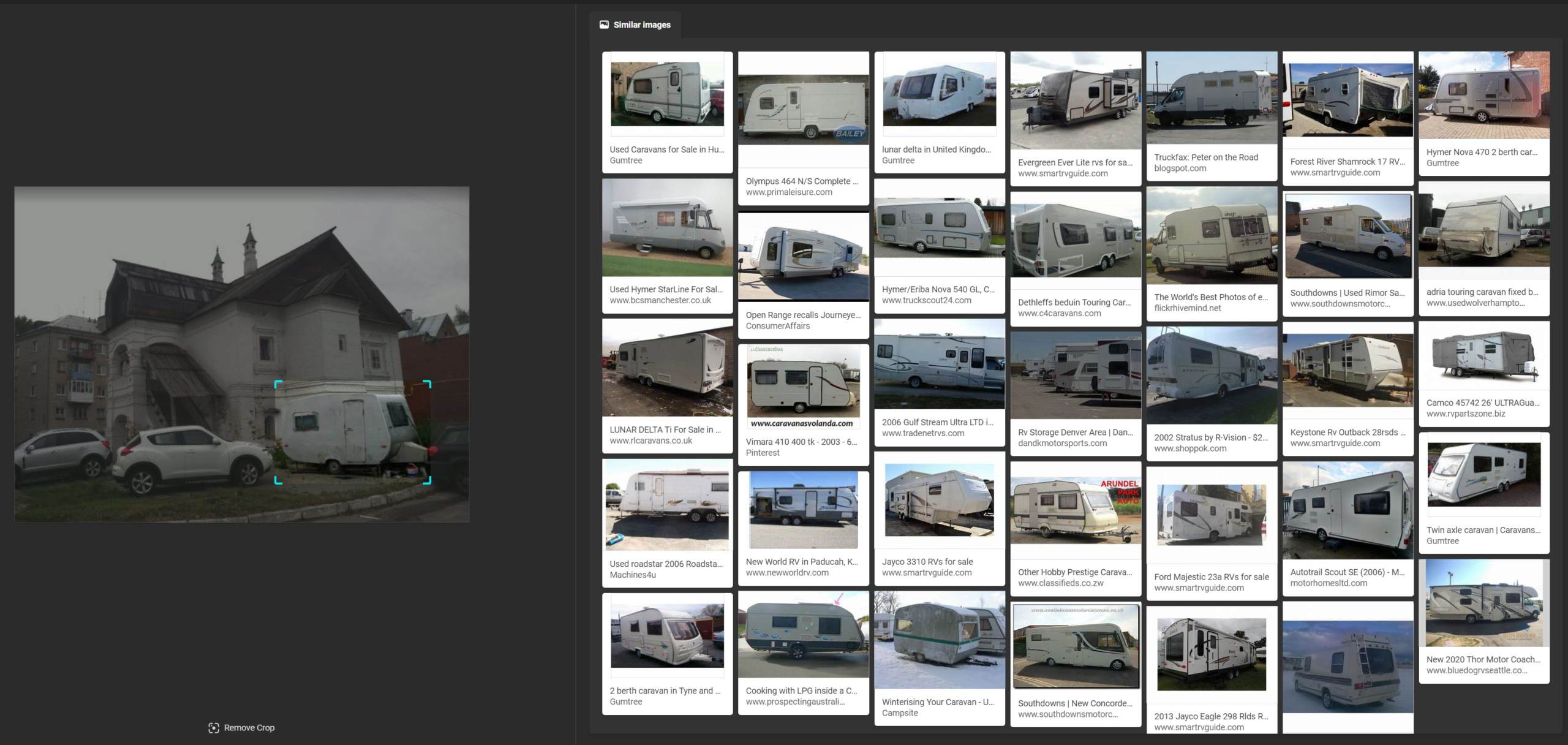
Lastly, Google recognized what the grey trailer was (travel trailer / camper), but its “visually similar images” were far from it.
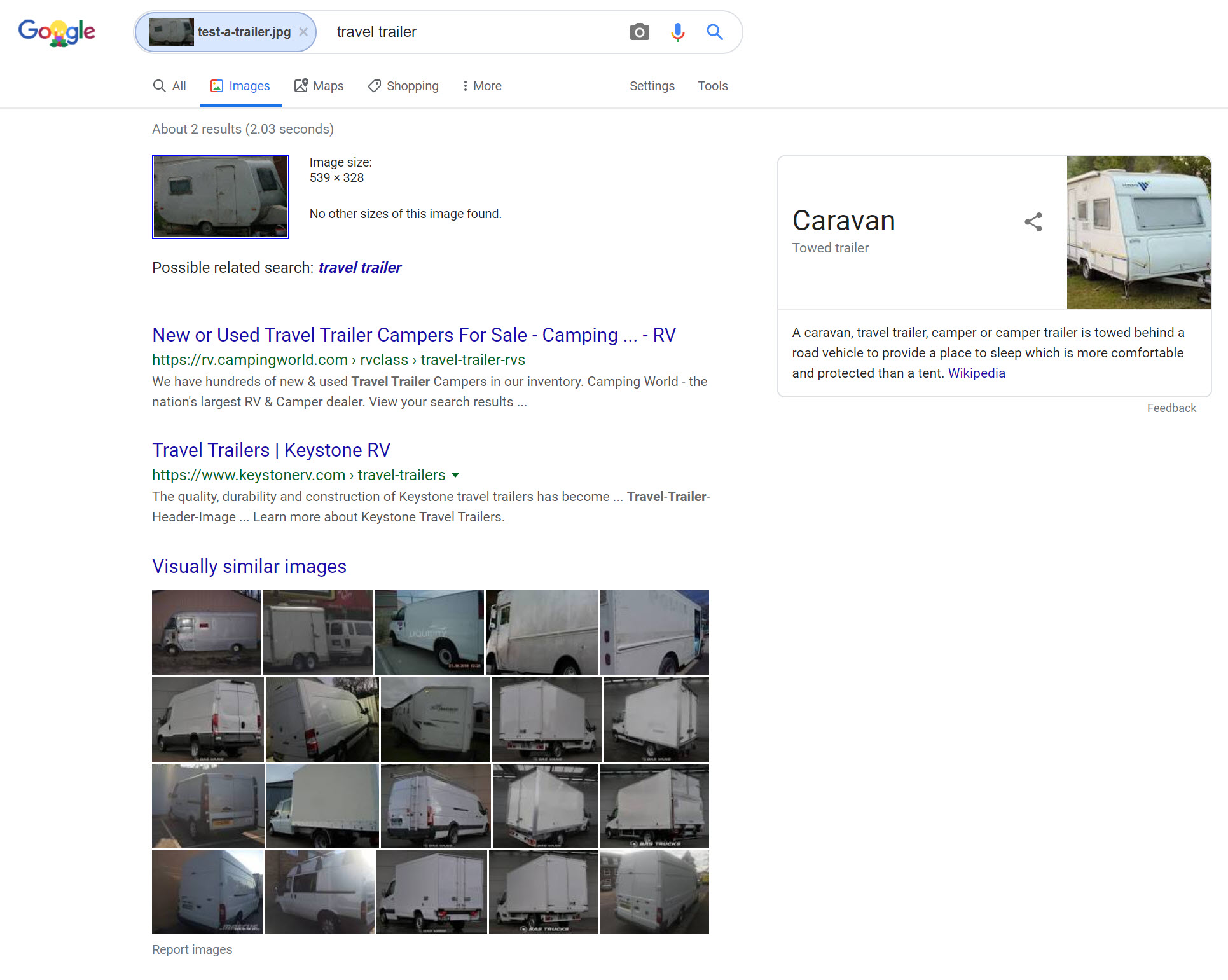
Scorecard: Yandex 2/3; Bing 0/3; Google 1/3
Cebu
Yandex was technically able to identify the cityscape as that of Cebu in the Philippines, but perhaps only by accident. The fourth result in the first row and the fourth result in the second row are of Cebu, but only the second photograph shows any of the same buildings as in the source image. Many of the results were also from southeast Asia (especially Thailand, which is a popular destination for Russian tourists), noting similar architectural styles, but none are from the same perspective as the source.
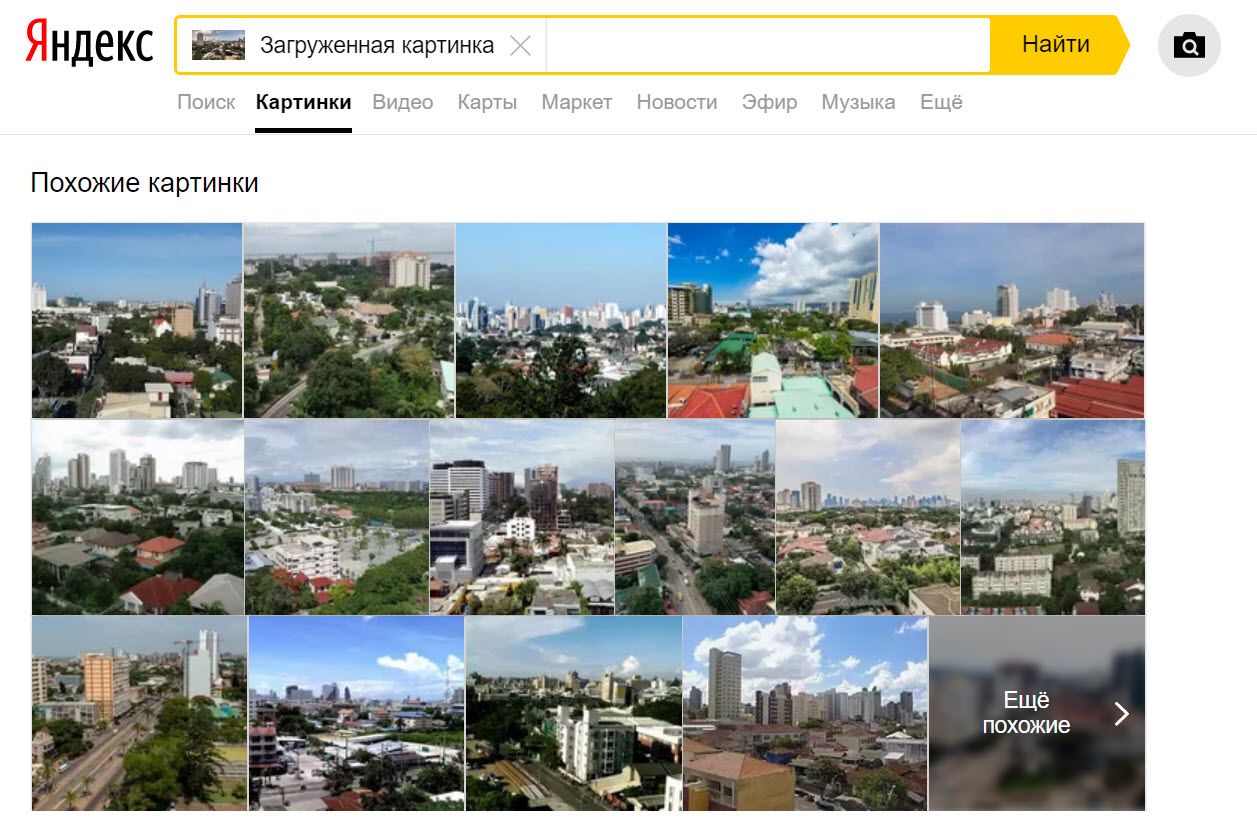
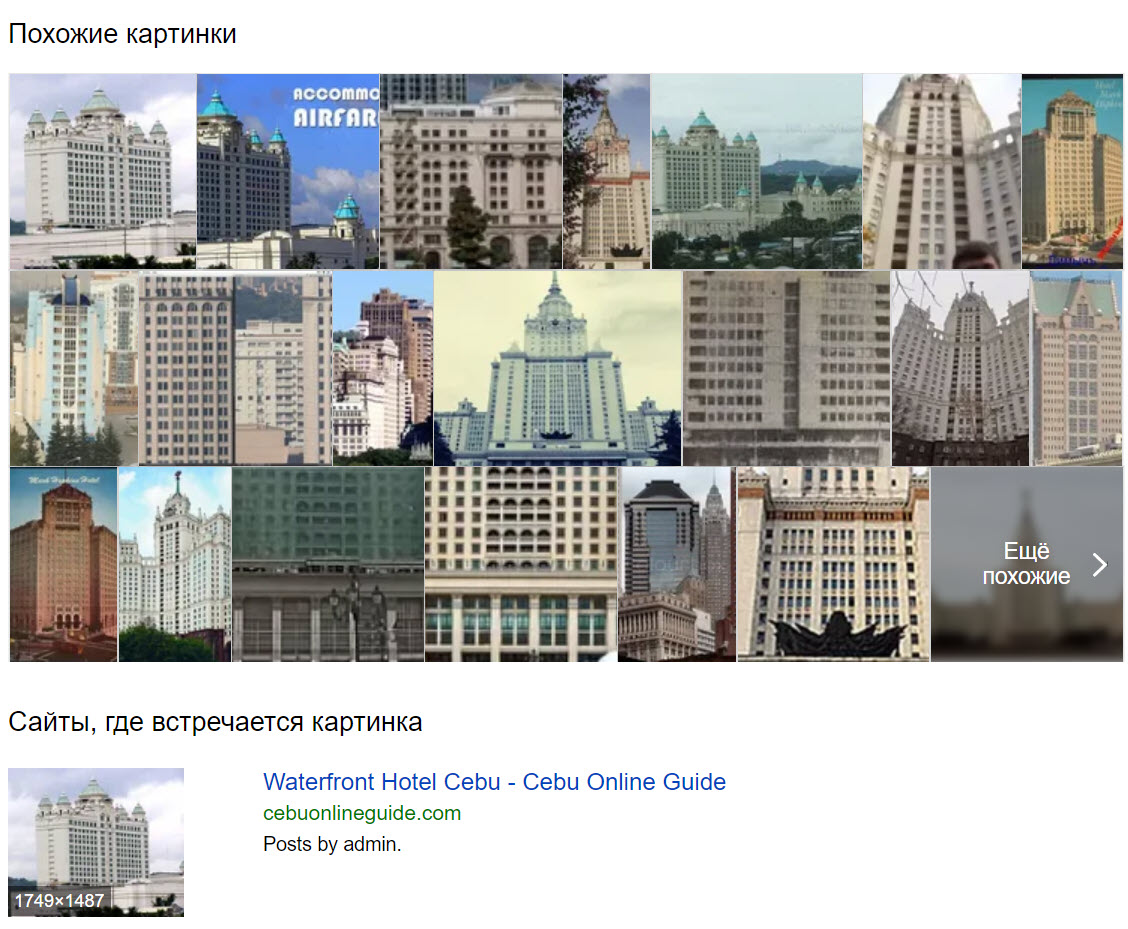
Of the two buildings isolated from the search (the Padgett Palace and Waterfront Hotel), Yandex was able to identify the latter, but not the former. The Padgett Palace building is a relatively unremarkable high-rise building filled with condos, while the Waterfront Hotel also has a casino inside, leading to an array of tourist photographs showing its more distinct architecture.

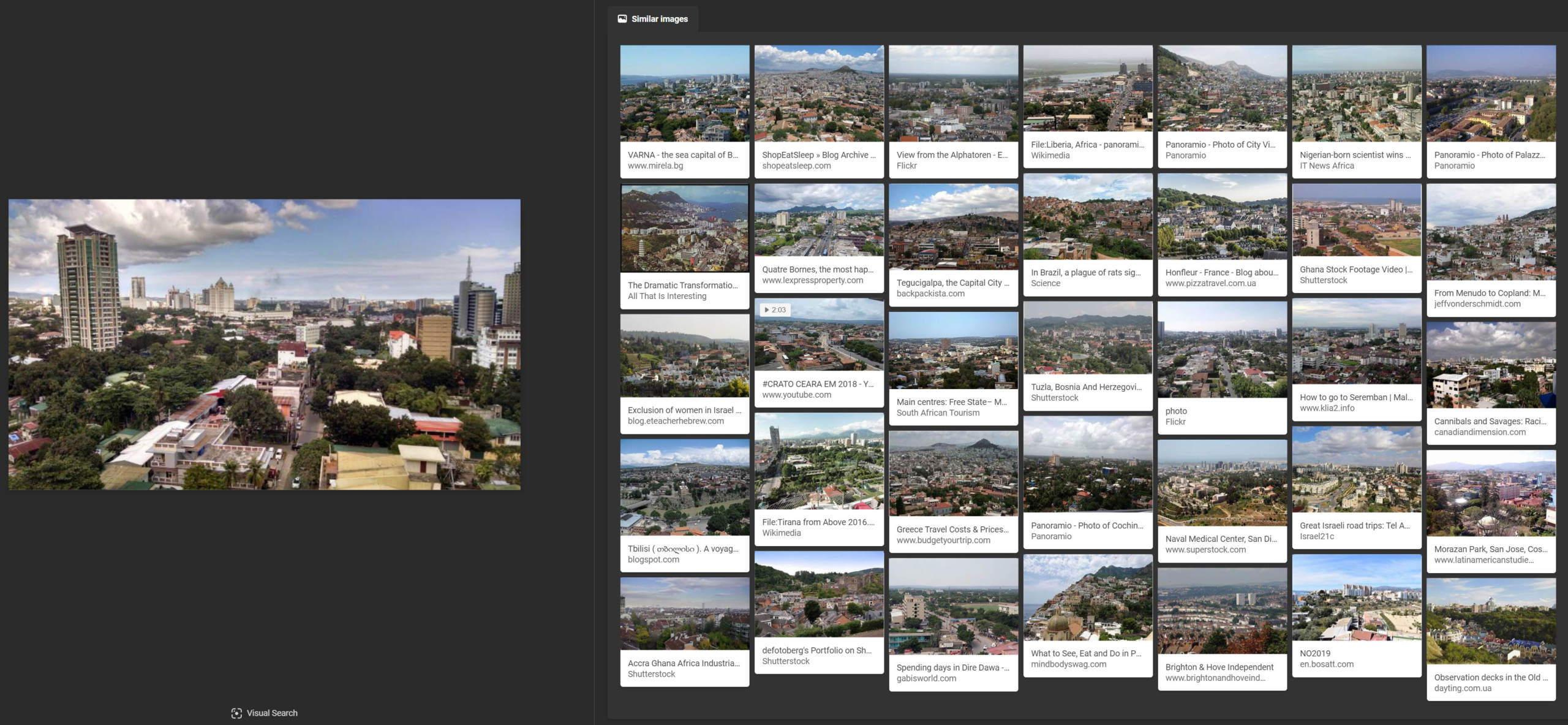
Bing did not have any results that were even in southeast Asia when searching for the Cebu cityscape, showing a severe geographic limitation to its indexed results.
Like Yandex, Bing was unable to identify the building on the left part of the source image.
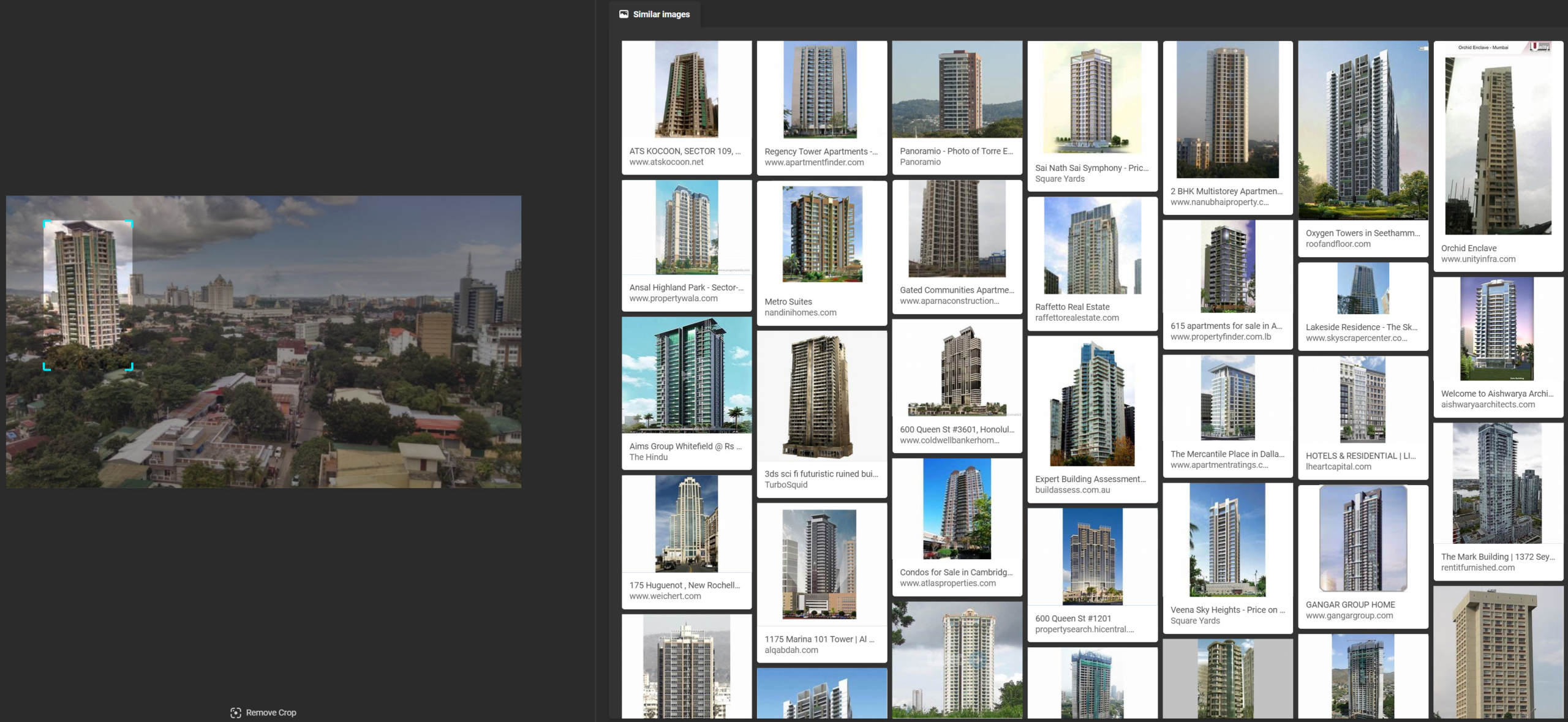
Bing was unable to find the Waterfront Hotel, both when using Bing’s cropping function (bringing back only low-resolution photographs) and manually cropping and increasing the resolution of the building from the source image. It is worth noting that the results from these two versions of the image, which were identical outside of the resolution, brought back dramatically different results.
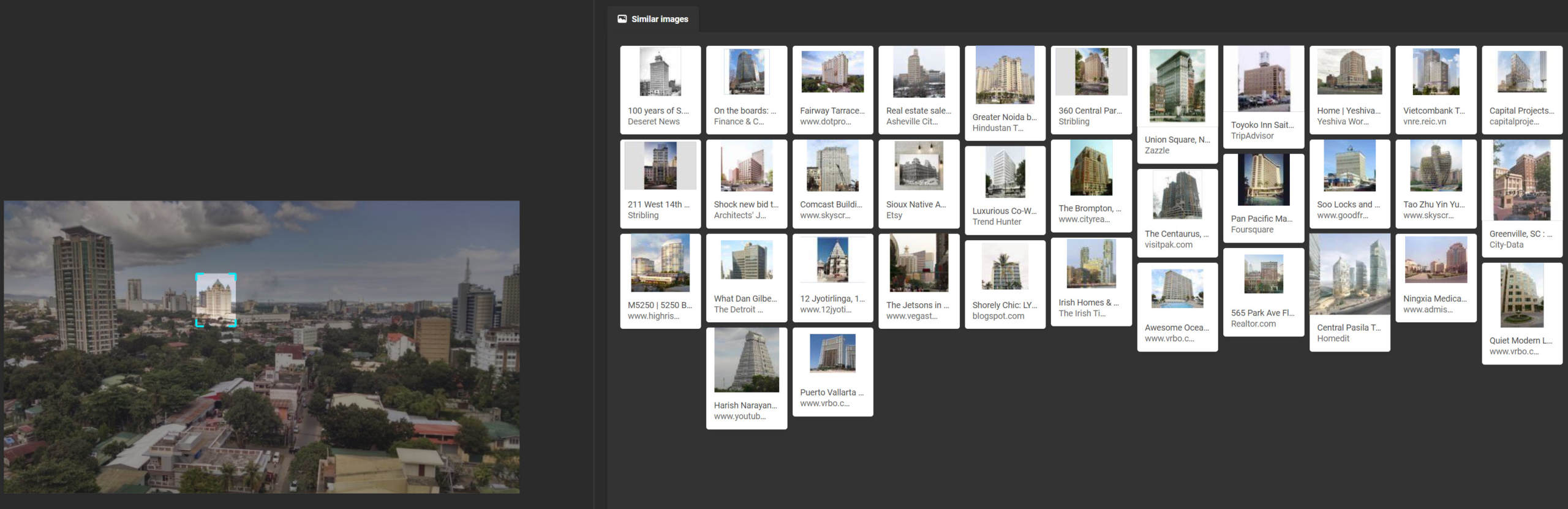
As with Yandex, Google brought back a photograph of Cebu in its results, but without a strong resemblance to the source image. While Cebu was not in the thumbnails for the initial results, following through to “Visually similar images” will fetch an image of Cebu’s skyline as the eleventh result (third image in the second row below).
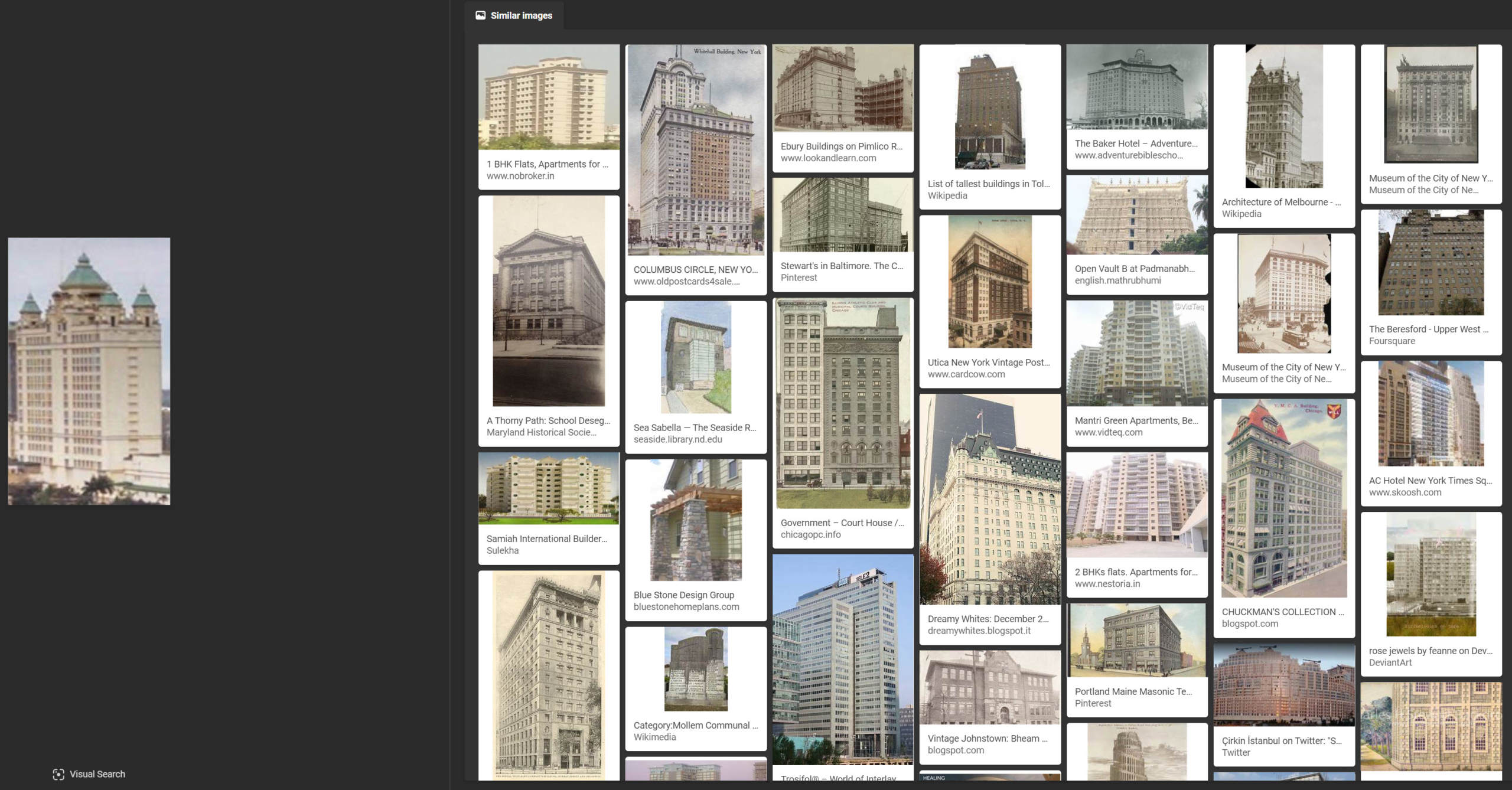
As with Yandex and Bing, Google was unable to identify the high-rise condo building on the left part of the source image. Google also had no success with the Waterfront Hotel image.
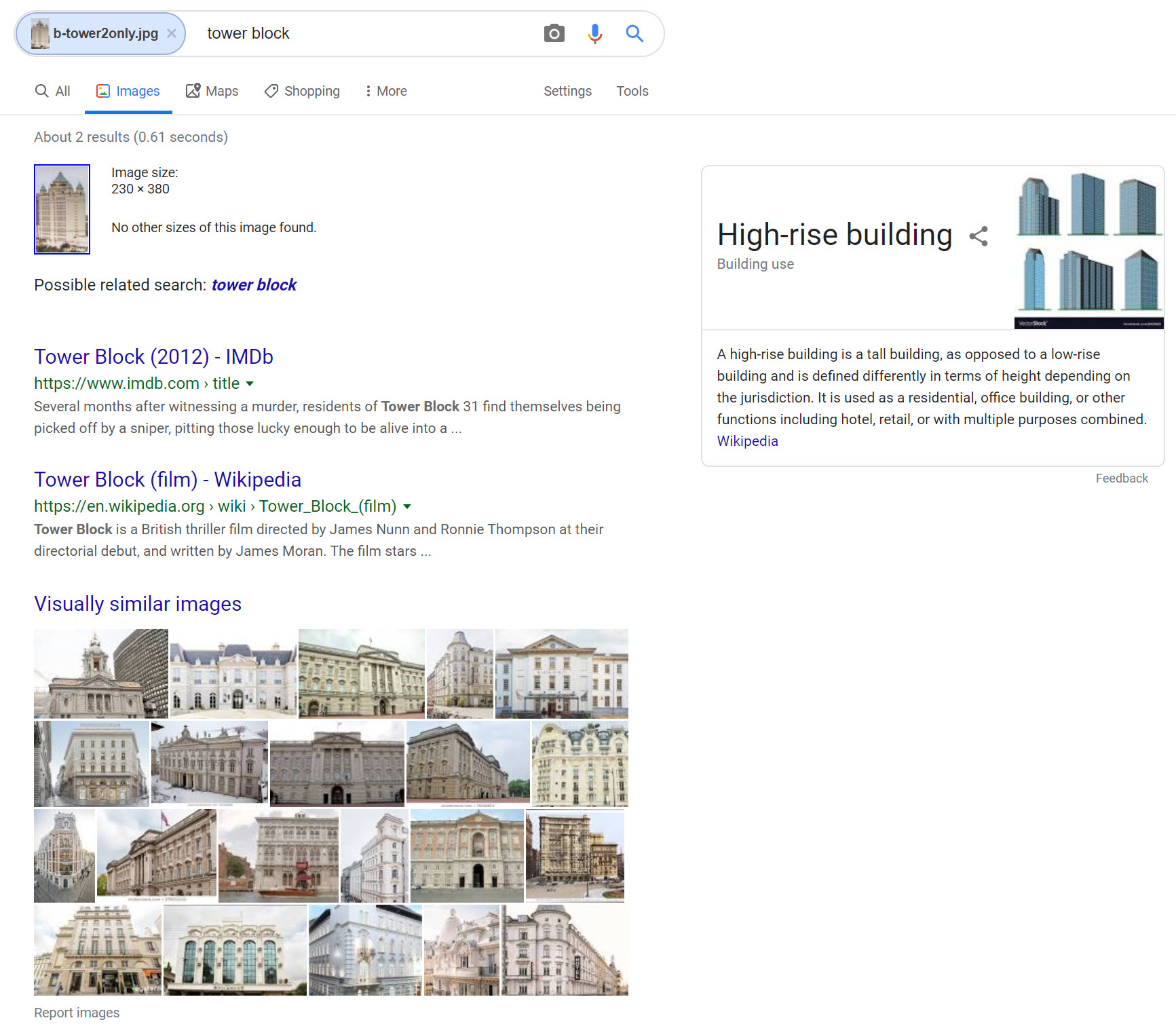
Scorecard: Yandex 4/6; Bing 0/6; Google 2/6
Bloomberg 2020 Student
Yandex found the source image from this Bloomberg campaign advertisement — a Getty Images stock photo. Along with this, Yandex also found versions of the photograph with filters applied (second result, first row) and additional photographs from the same stock photo series. Also, for some reason, porn, as seen in the blurred results below.
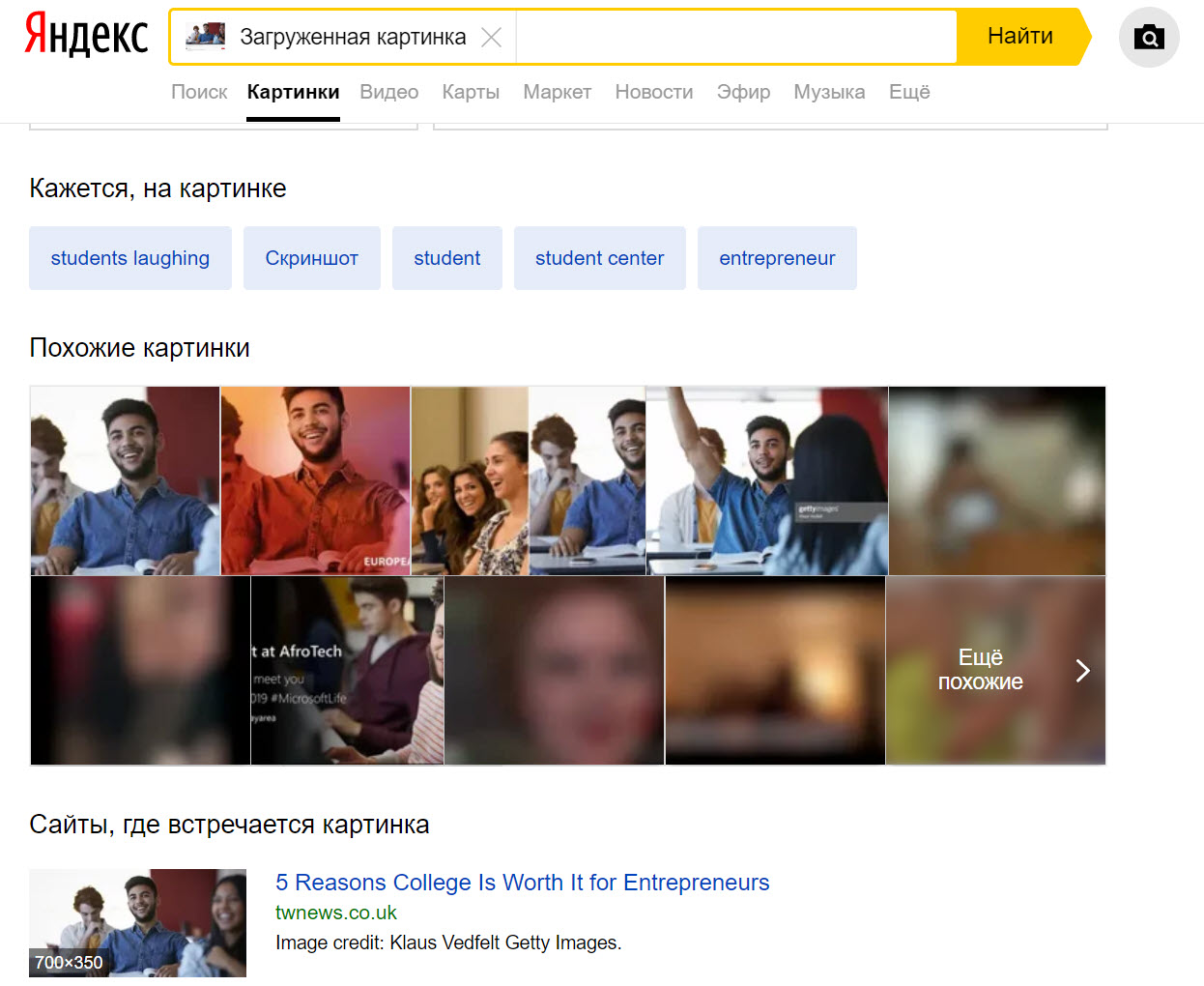
When isolating just the face of the stock photo model, Yandex brought back a handful of other shots of the same guy (see last image in first row), plus images of the same stock photo set in the classroom (see the fourth image in the first row).

Bing had an interesting search result: it found the exact match of the stock photograph, and then brought back “Similar images” of other men in blue shirts. The “Pages with this” tab of the result provides a handy list of duplicate versions of this same image across the web.
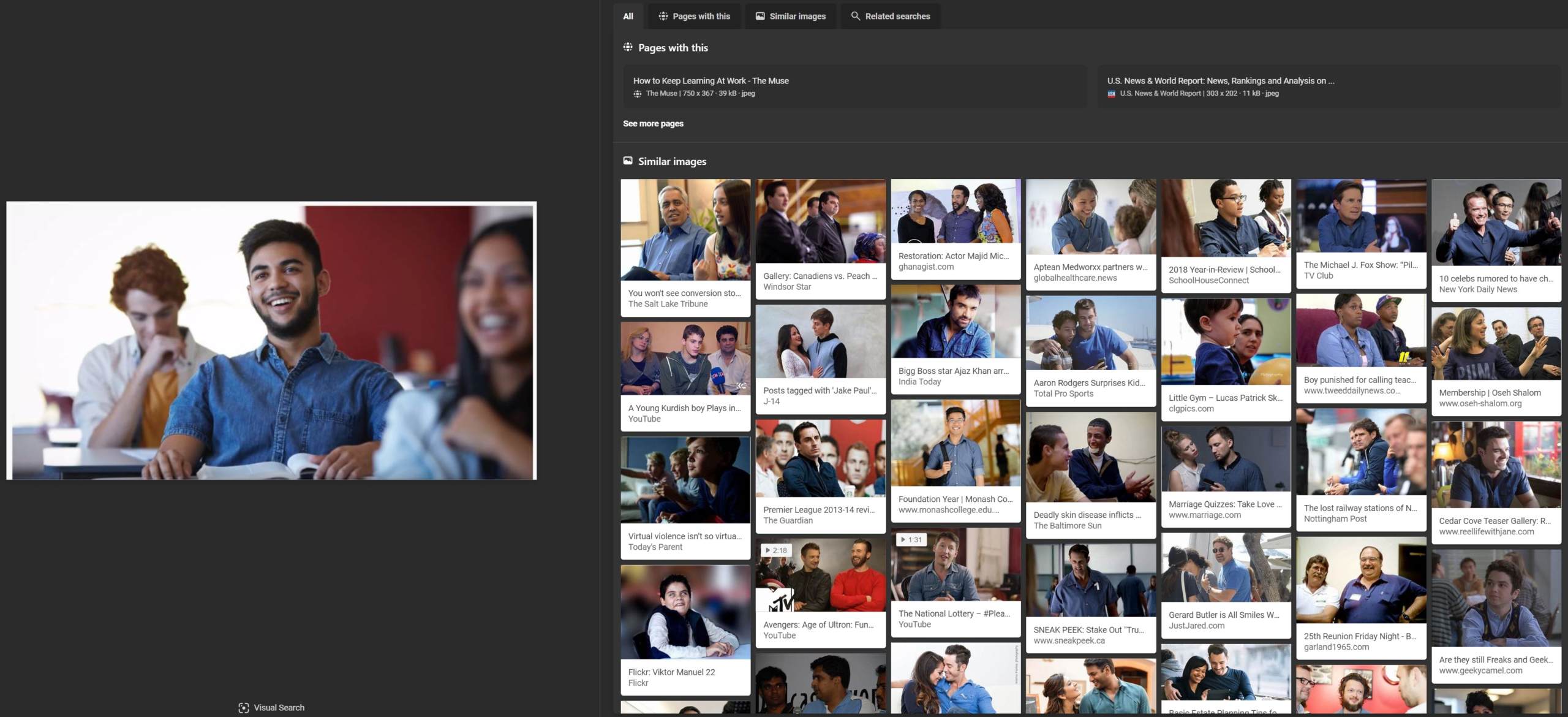
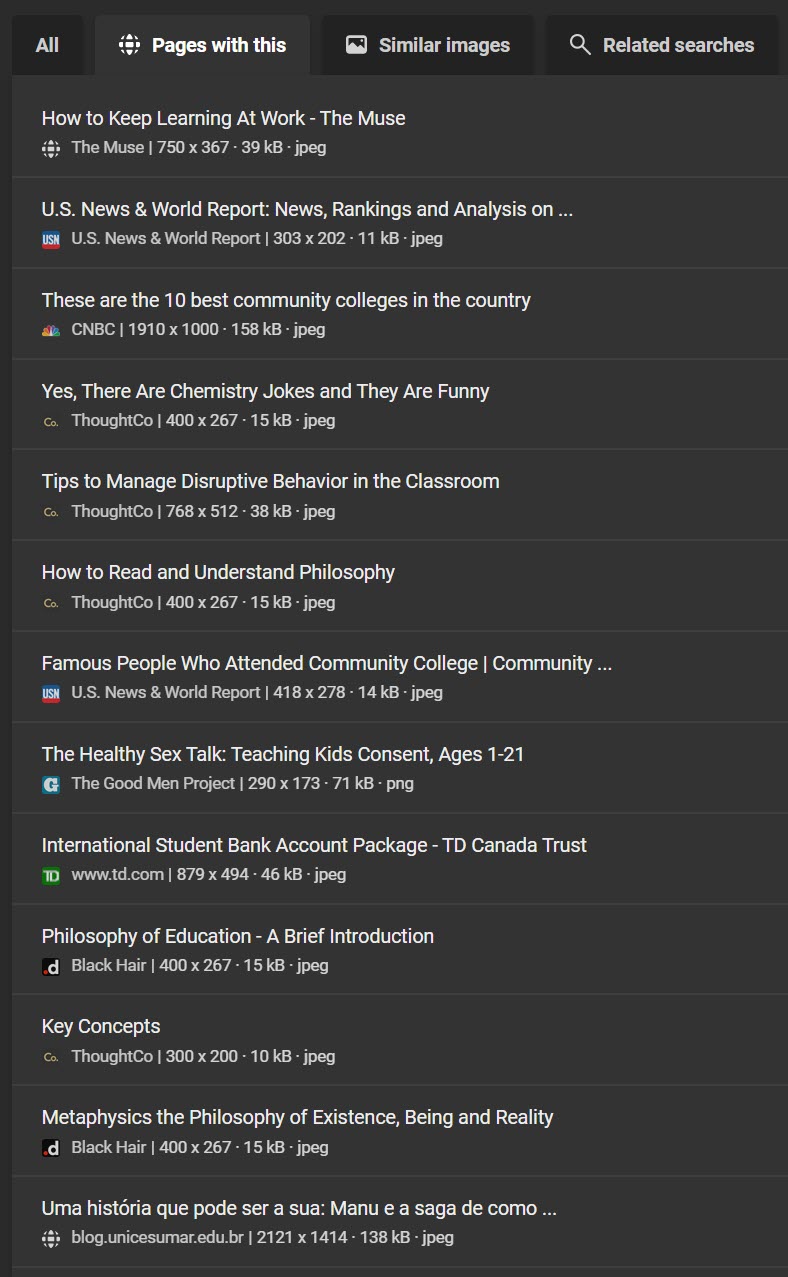
Focusing on just the face of the stock photo model does not bring back any useful results, or provide the source image that it was taken from.
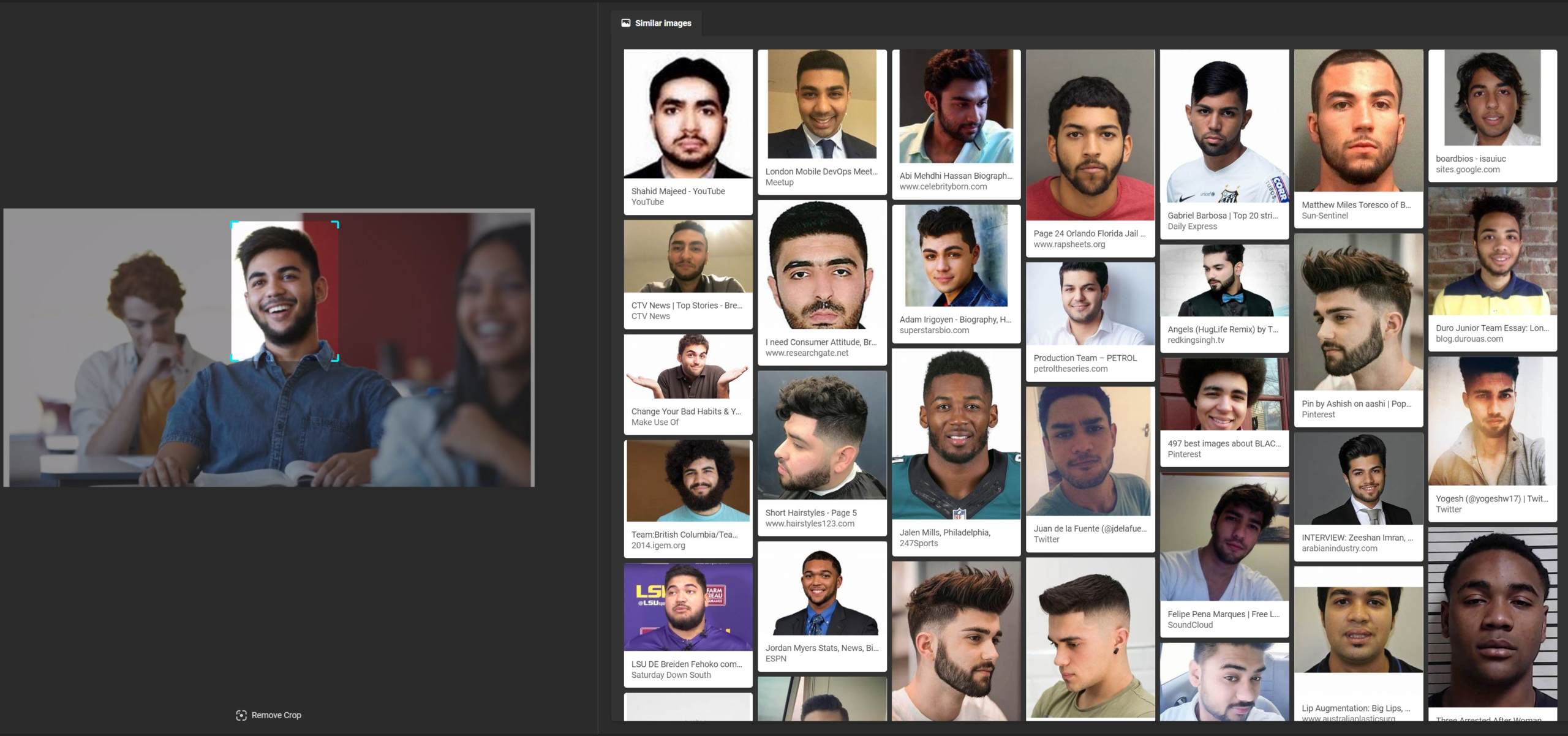
Google recognizes that the image used by the Bloomberg campaign is a stock photo, bringing back an exact result. Google will also provide other stock photos of people in blue shirts in class.
In isolating the student, Google will again return the source of the stock photo, but its visually similar images do not show the stock photo model, rather an array of other men with similar facial hair. We’ll count this as a half-win in finding the original image, but not showing any information on the specific model, as Yandex did.

Scorecard: Yandex 6/8; Bing 1/8; Google 3.5/8
Brazilian Street View
Yandex could not figure out that this image was snapped in Brazil, instead focusing on urban landscapes in Russia.
For Toca do Açaí, for some reason, Yandex mostly brought back porn as results. These images were blurred, and you can click here to see the results. However, despite the blurred smut, two of the results did correctly identify the logo.
For the parking sign [Estacionamento], Yandex did not even come close.

Bing did not know that this street view image was taken in Brazil.
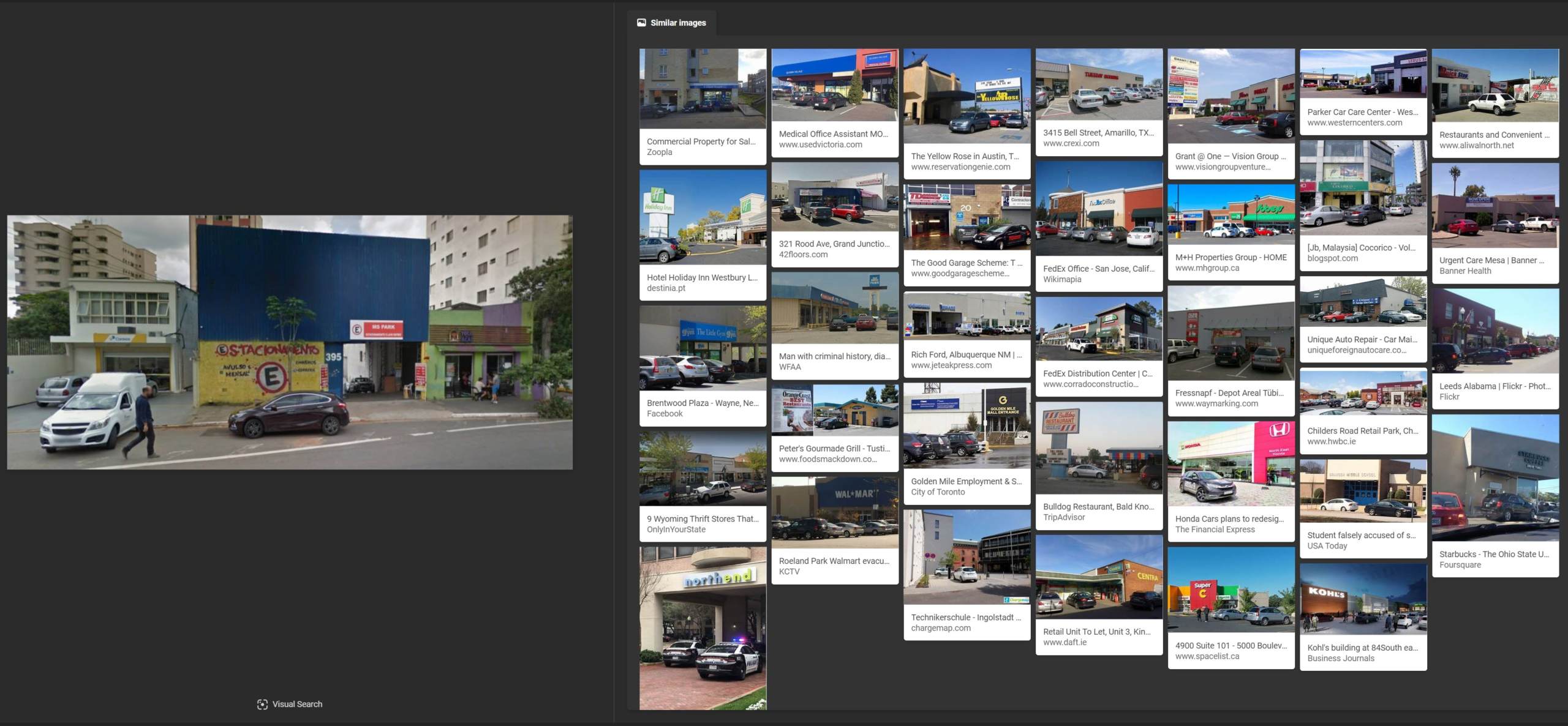
…nor did Bing recognize the parking sign…
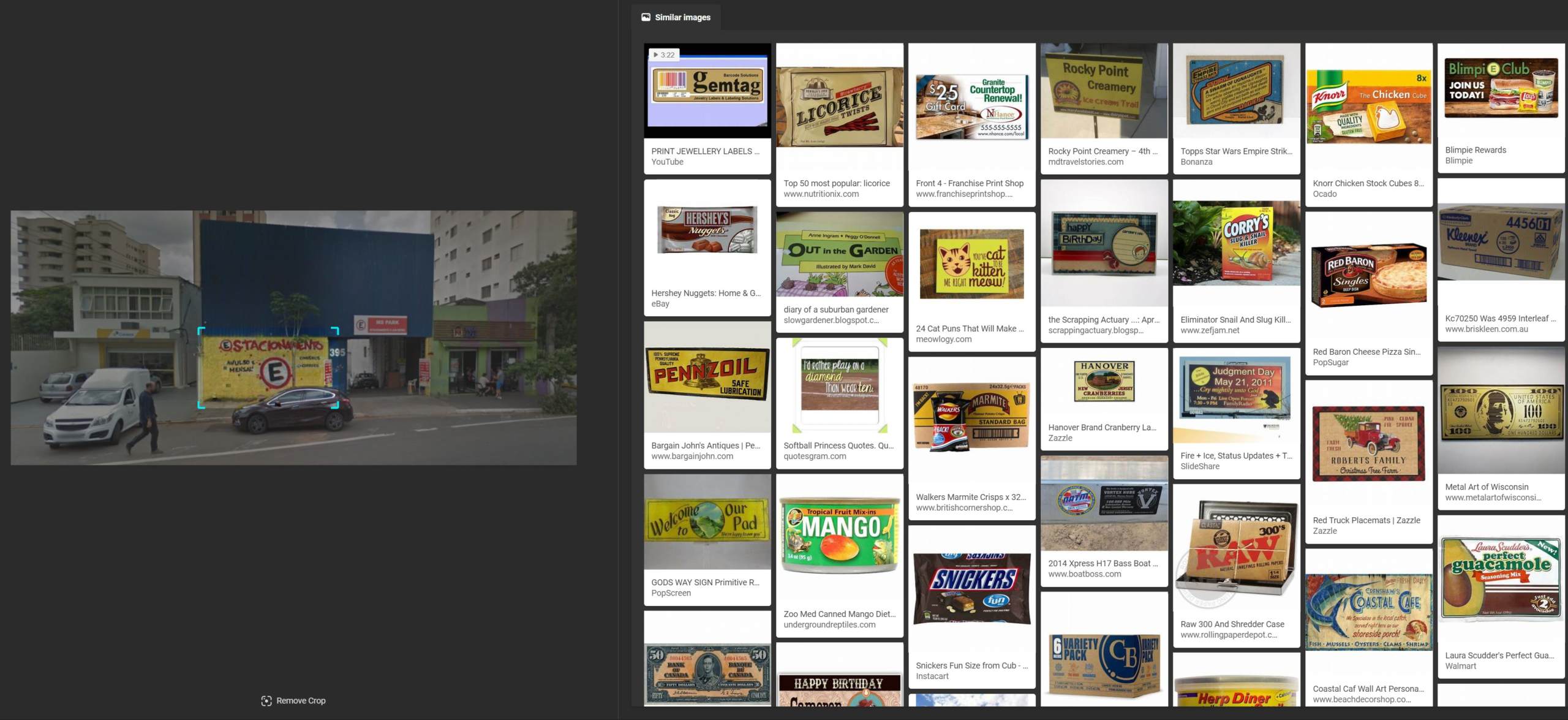
…or the Toca do Açaí logo.
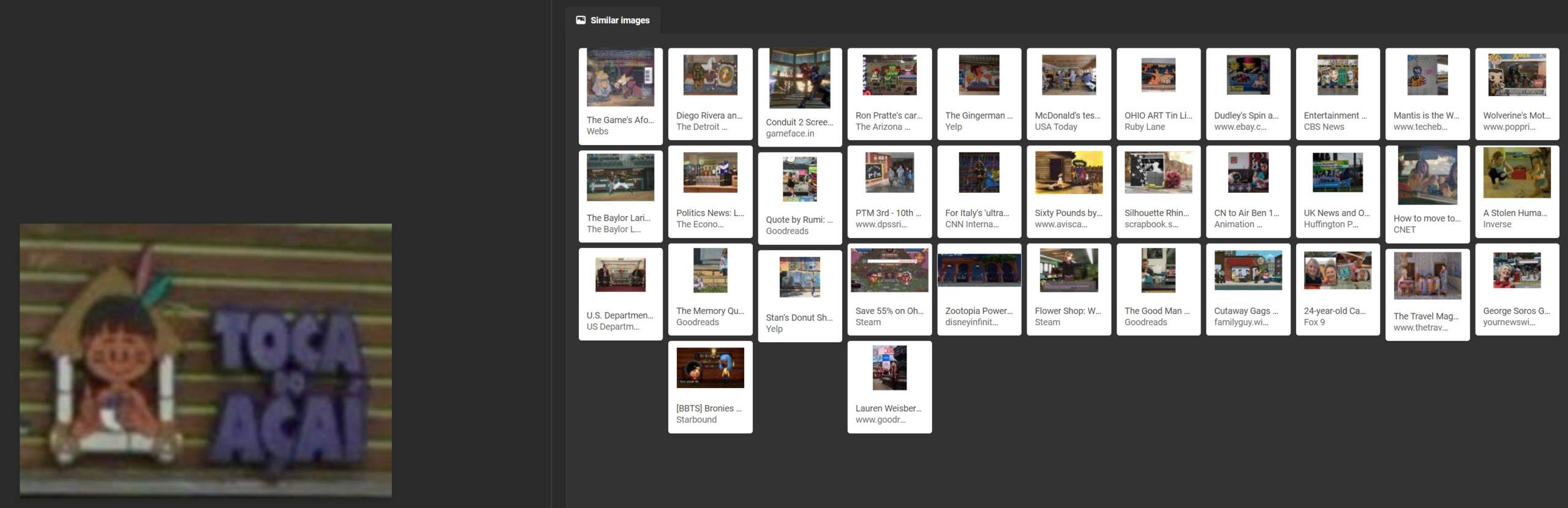
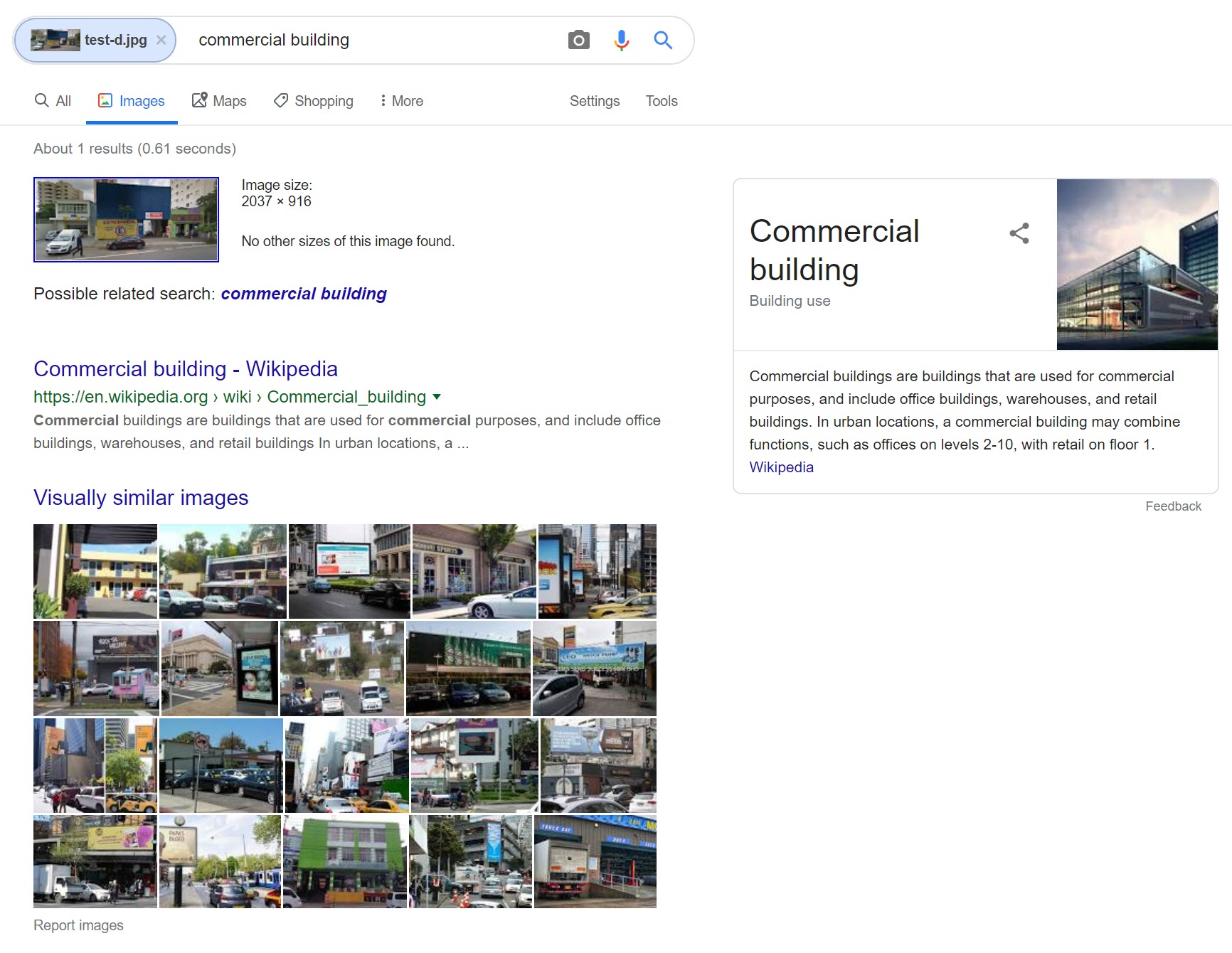
Despite the fact that the image was directly taken from Google’s Street View, Google reverse image search did not recognize a photograph uploaded onto its own service.
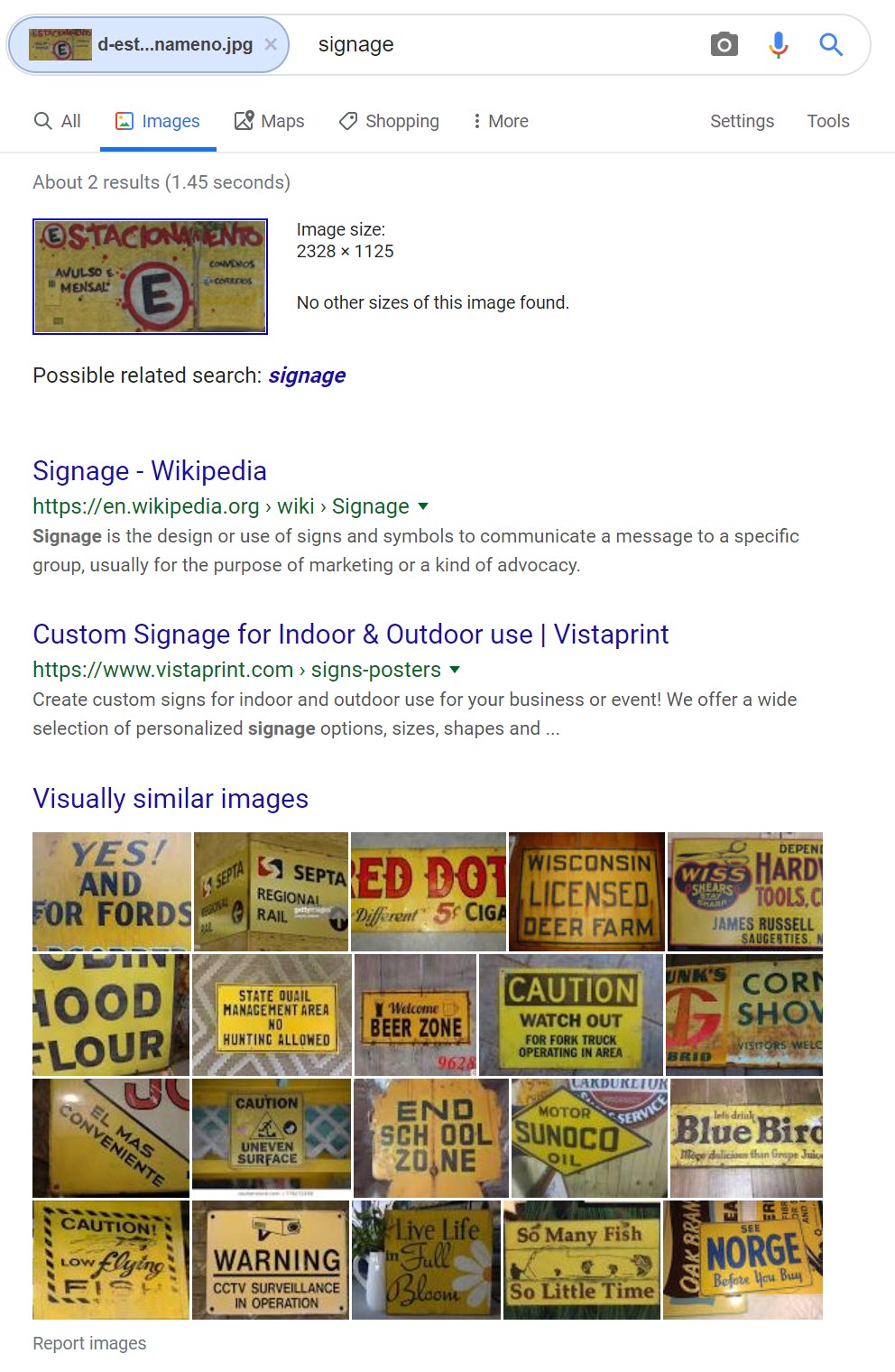
Just as Bing and Yandex, Google could not recognize the Portuguese parking sign.
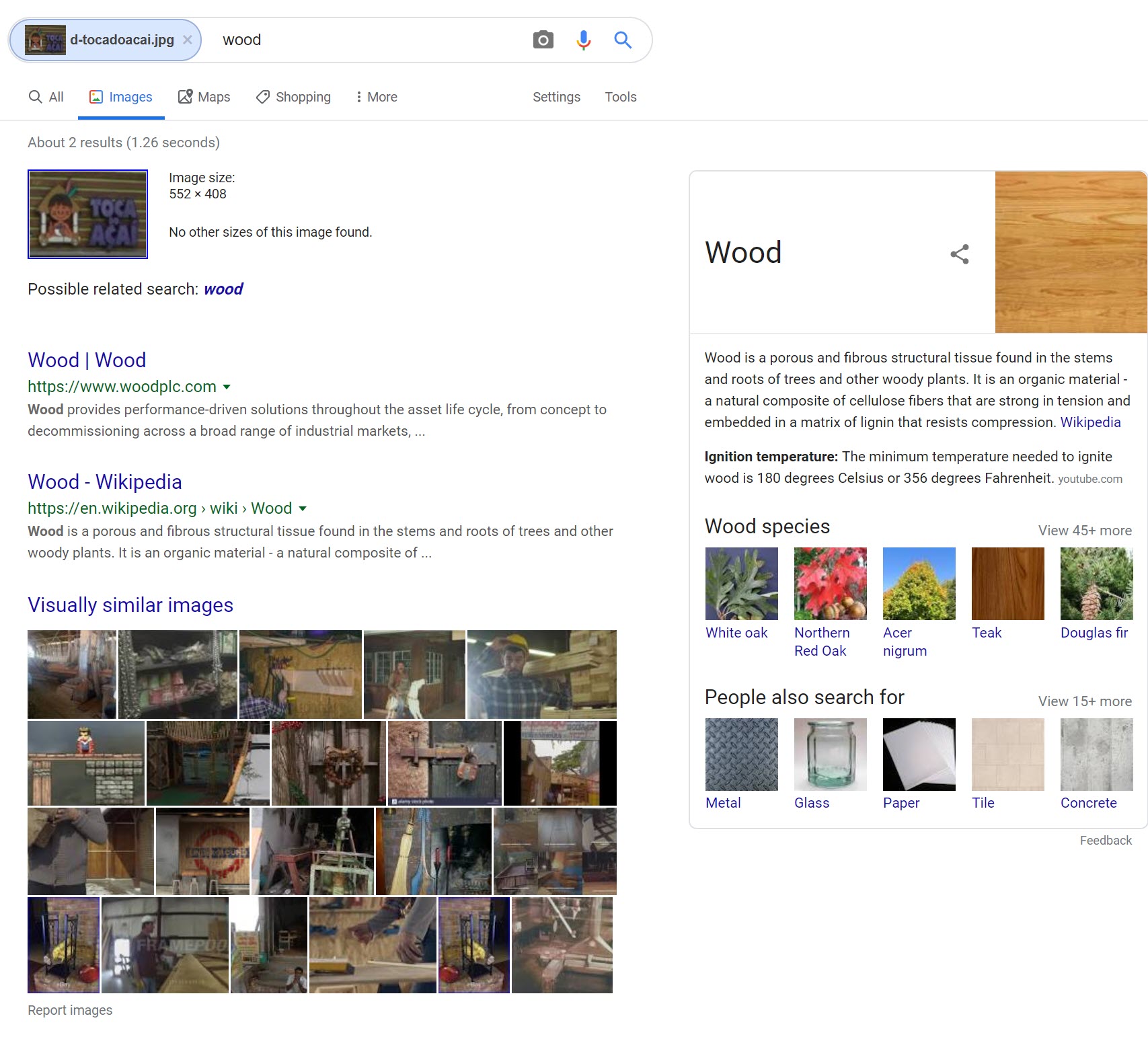
Lastly, Google did not come close to identifying the Toca do Açaí logo, instead focusing on various types of wooden panels, showing how it focused on the backdrop of the image rather than the logo and words.
Scorecard: Yandex 7/11; Bing 1/11; Google 3.5/11
Amsterdam Canal
Yandex knew exactly where this photograph was taken in Amsterdam, finding other photographs taken in central Amsterdam, and even including ones with various types of birds in the frame.
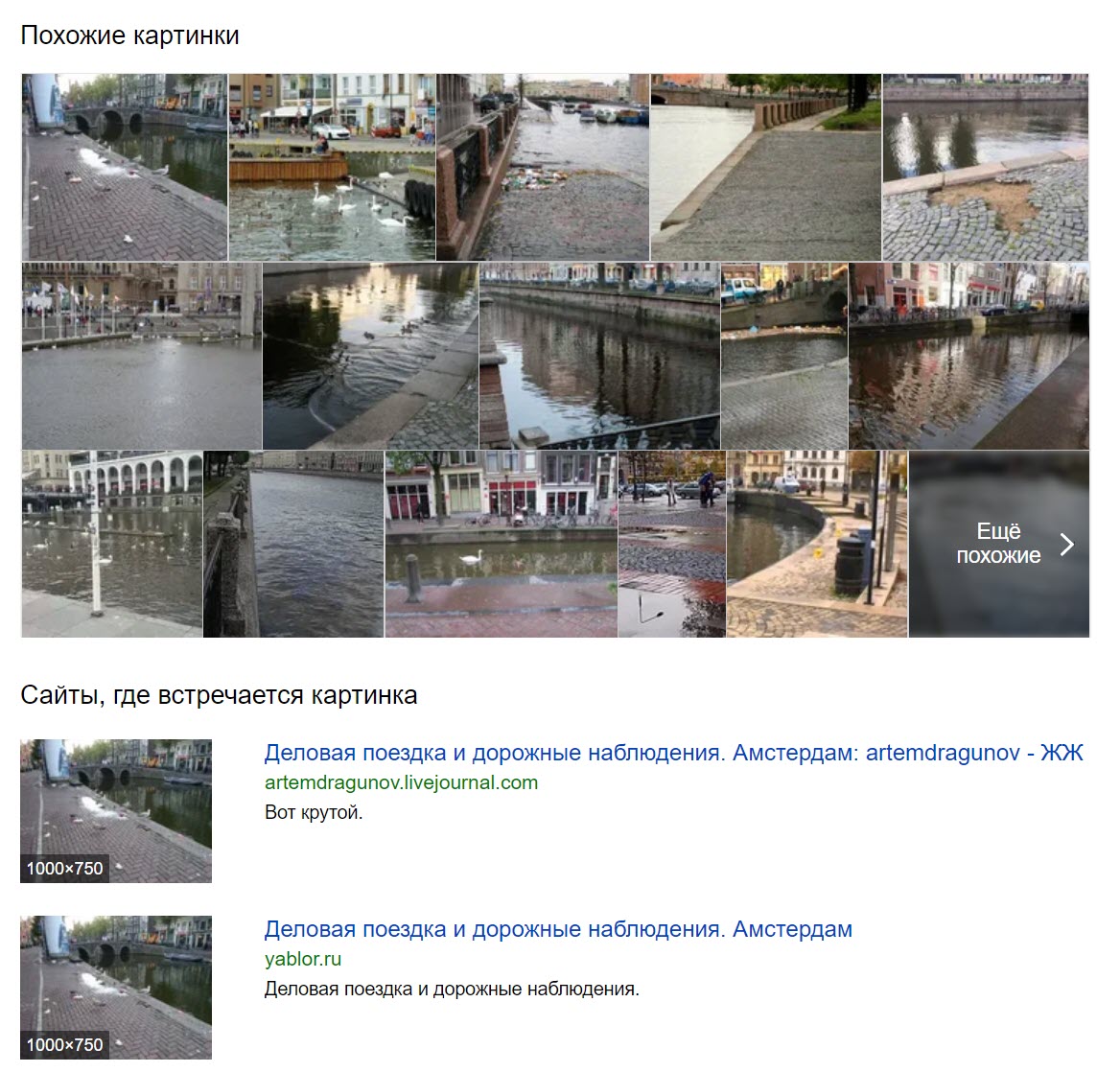
Yandex correctly identified bird in the foreground of the photograph as a grey heron (серая цапля), also bringing back an array of images of grey herons in a similar position and posture as the source image.
However, Yandex flunked the test of identifying the Dutch flag hanging in the background of the photograph. When rotating the image 90 degrees clockwise to present the flag in its normal pattern, Yandex was able to figure out that it was a flag, but did not return any Dutch flags in its results.



Bing only recognized that this image shows an urban landscape with water, with no results from Amsterdam.
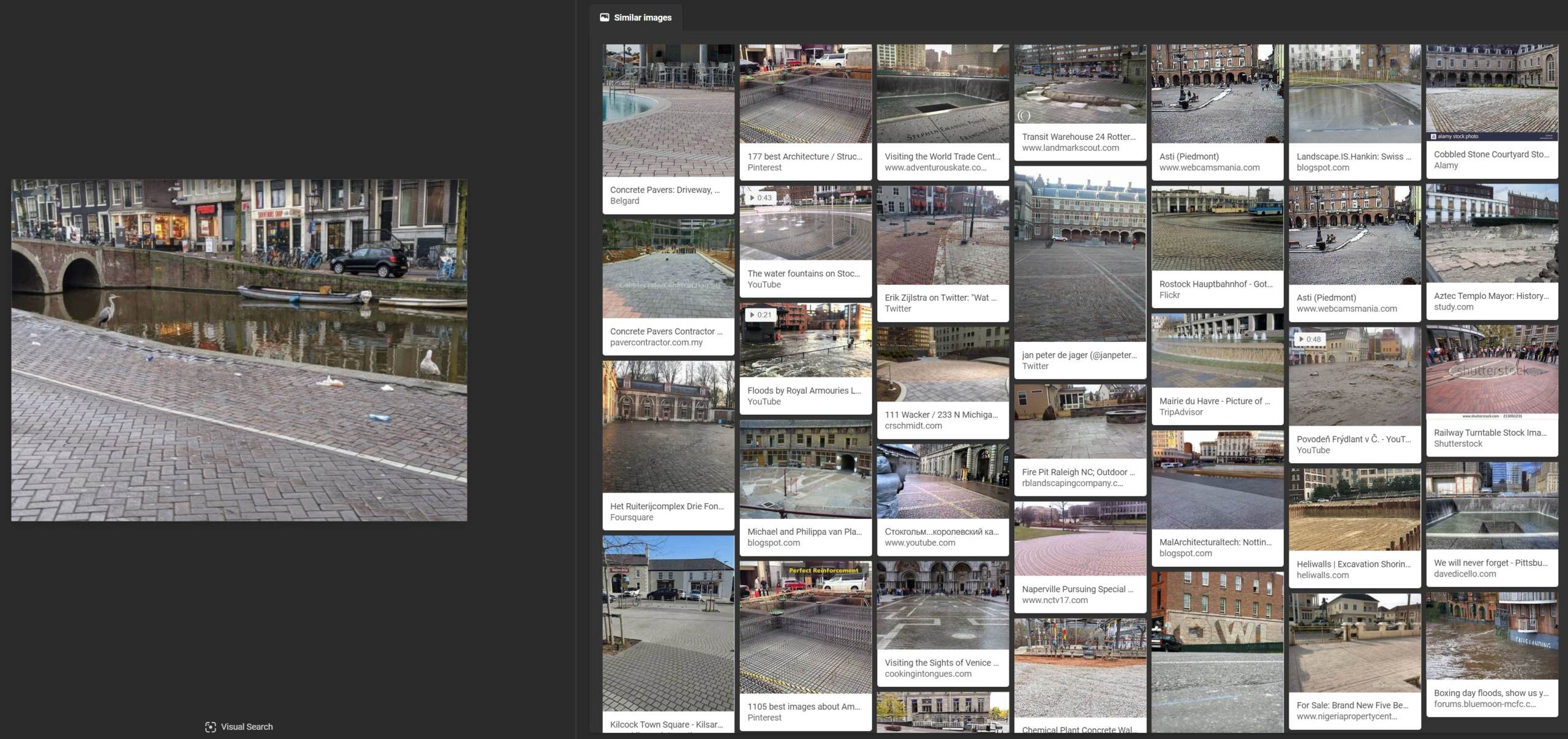
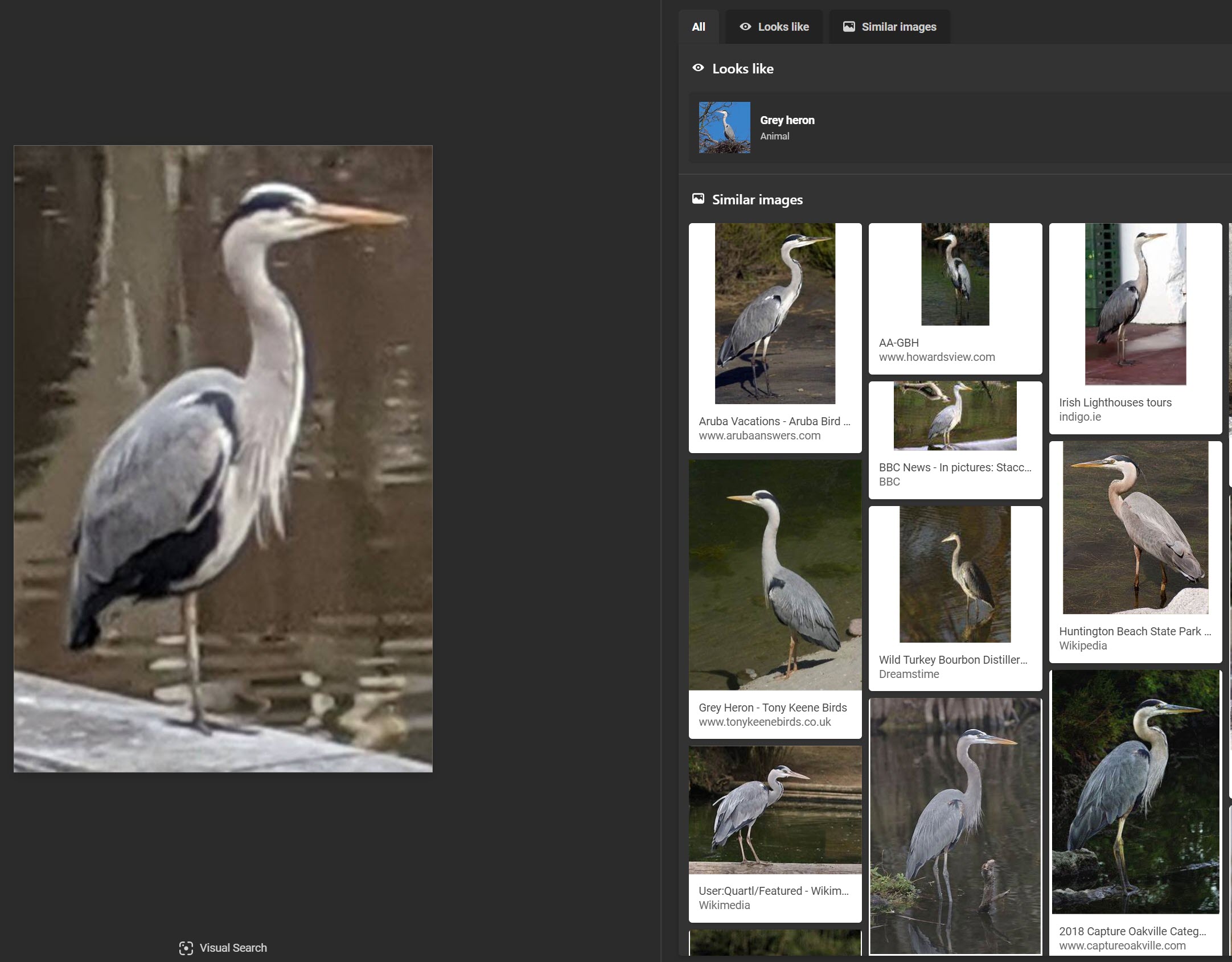
Though Bing struggled with identifying an urban landscape, it correctly identified the bird as a grey heron, including a specialized “Looks like” result going to a page describing the bird.
However, like with Yandex, the Dutch flag was too confusing for Bing, both in its original and rotated forms.
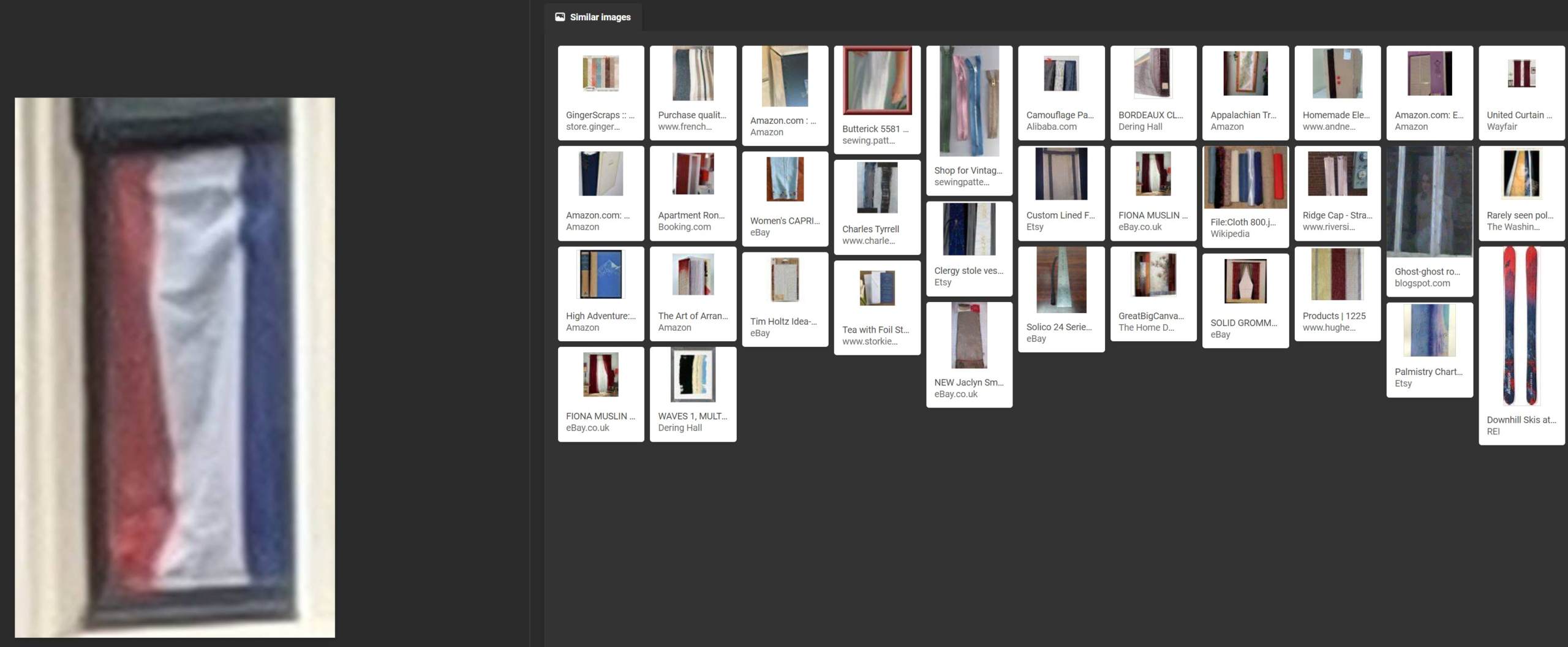
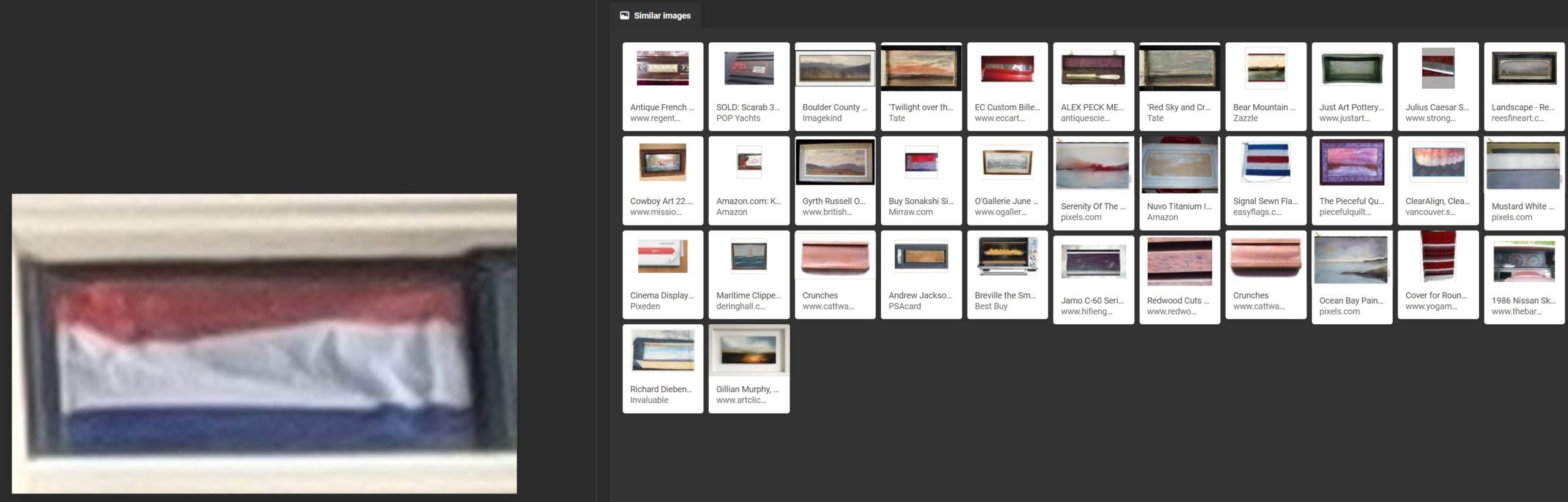
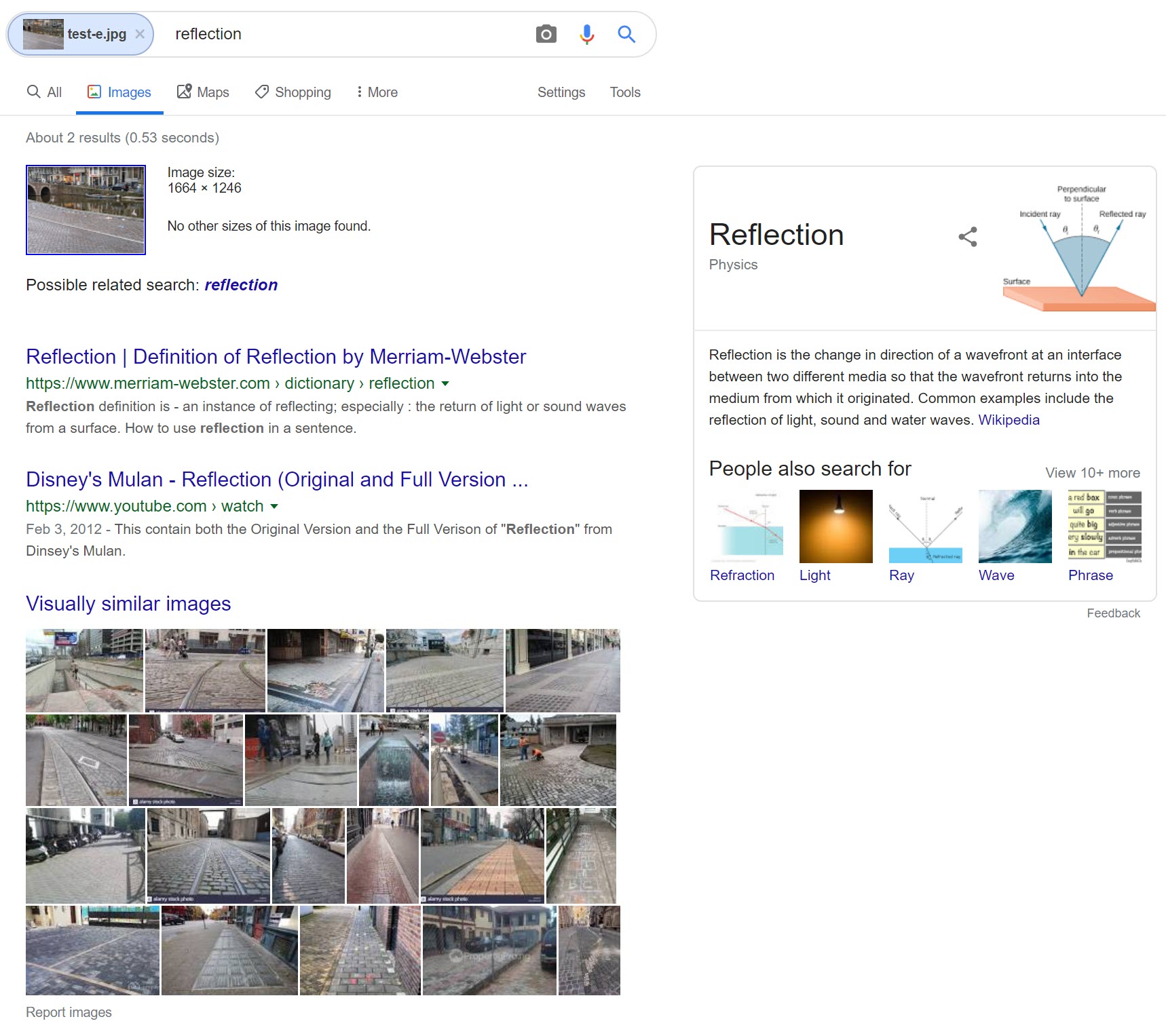
Google noted that there was a reflection in the canal of the image, but went no further than this, focusing on various paved paths in cities and nothing from Amsterdam.
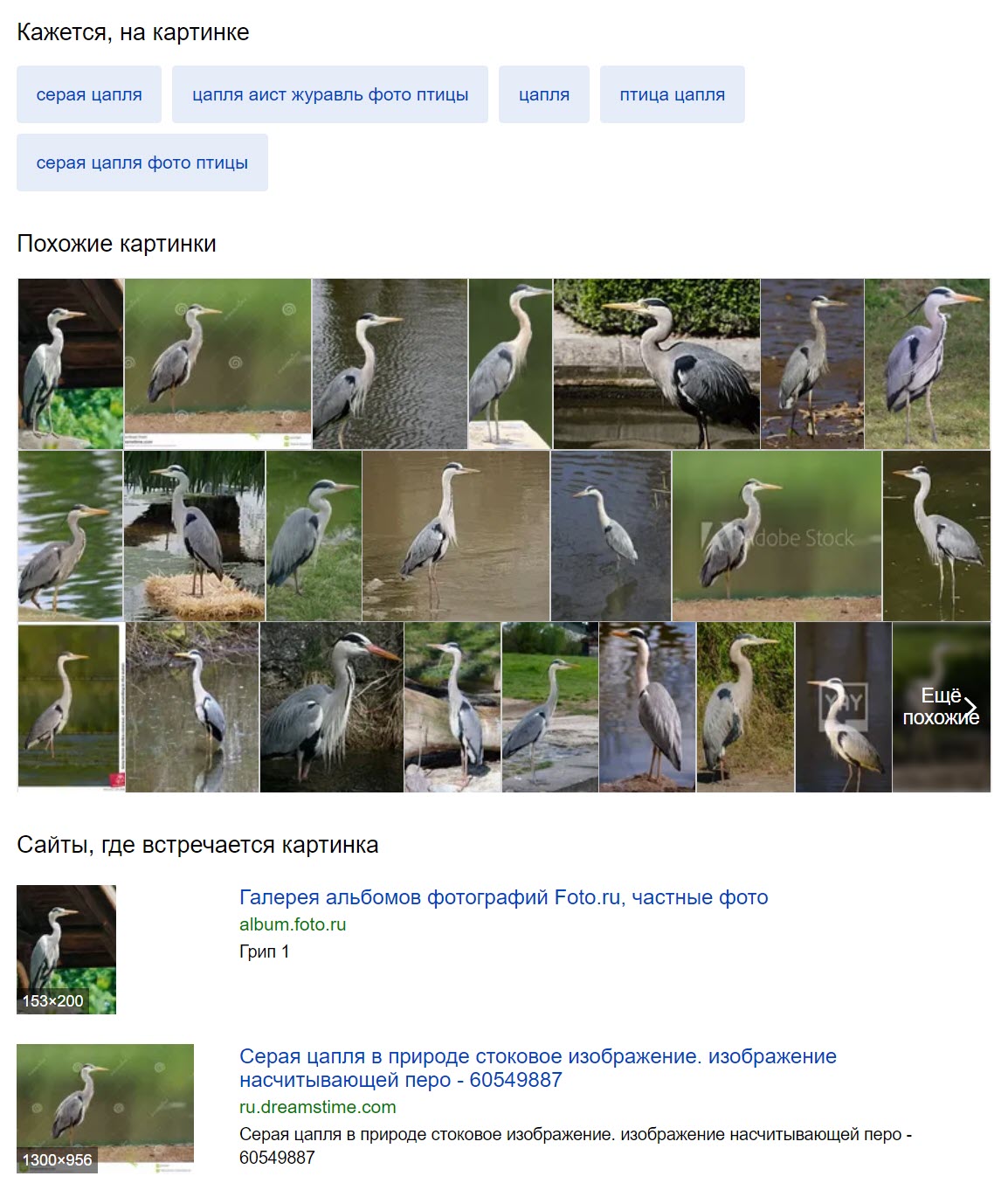
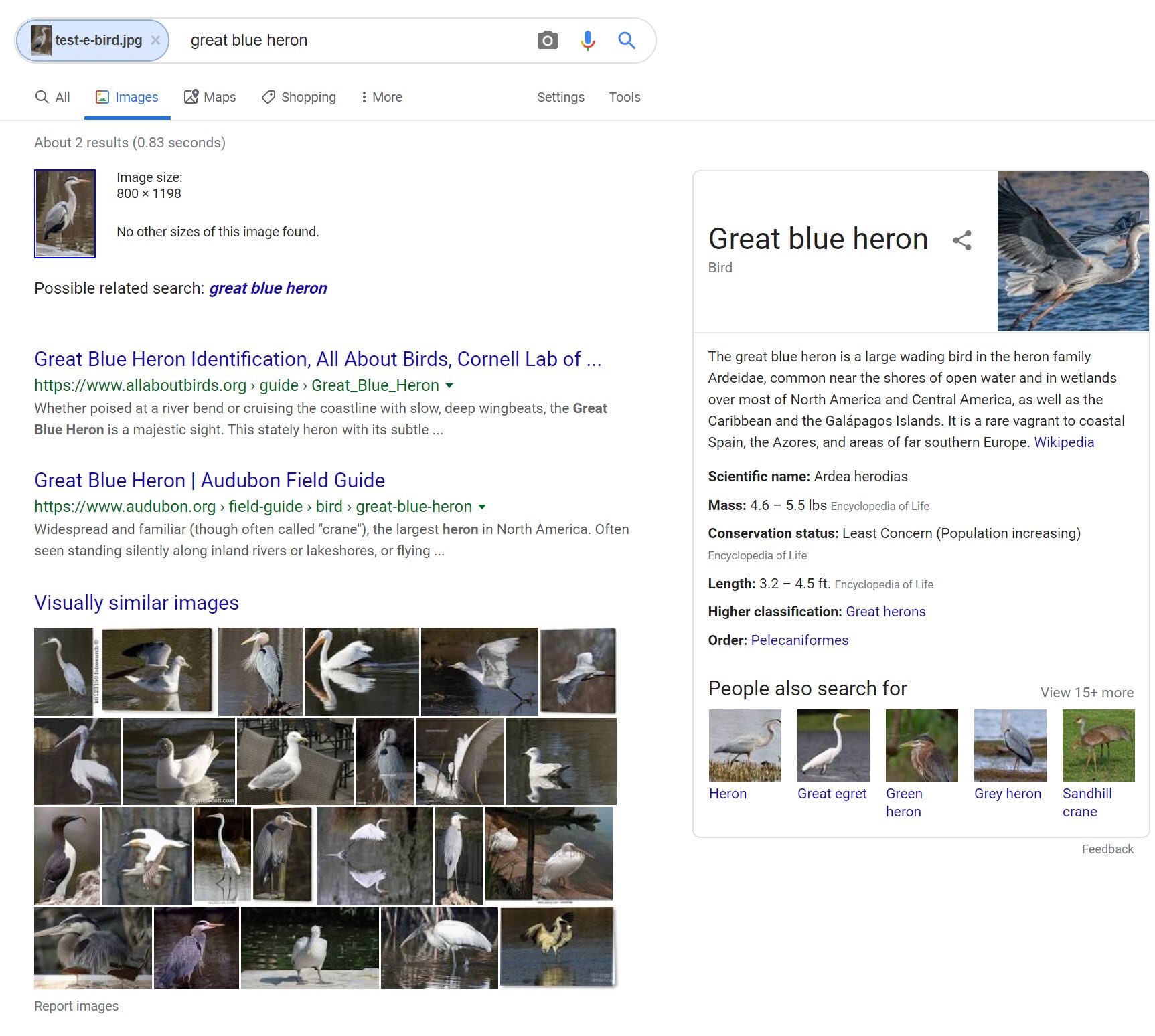
Google was close in the bird identification exercise, but just barely missed it — it is a grey, not great blue, heron.
Google was also unable to identify the Dutch flag. Though Yandex seemed to recognize that the image is a flag, Google’s algorithm focused on the windowsill framing the image and misidentified the flag as curtains.
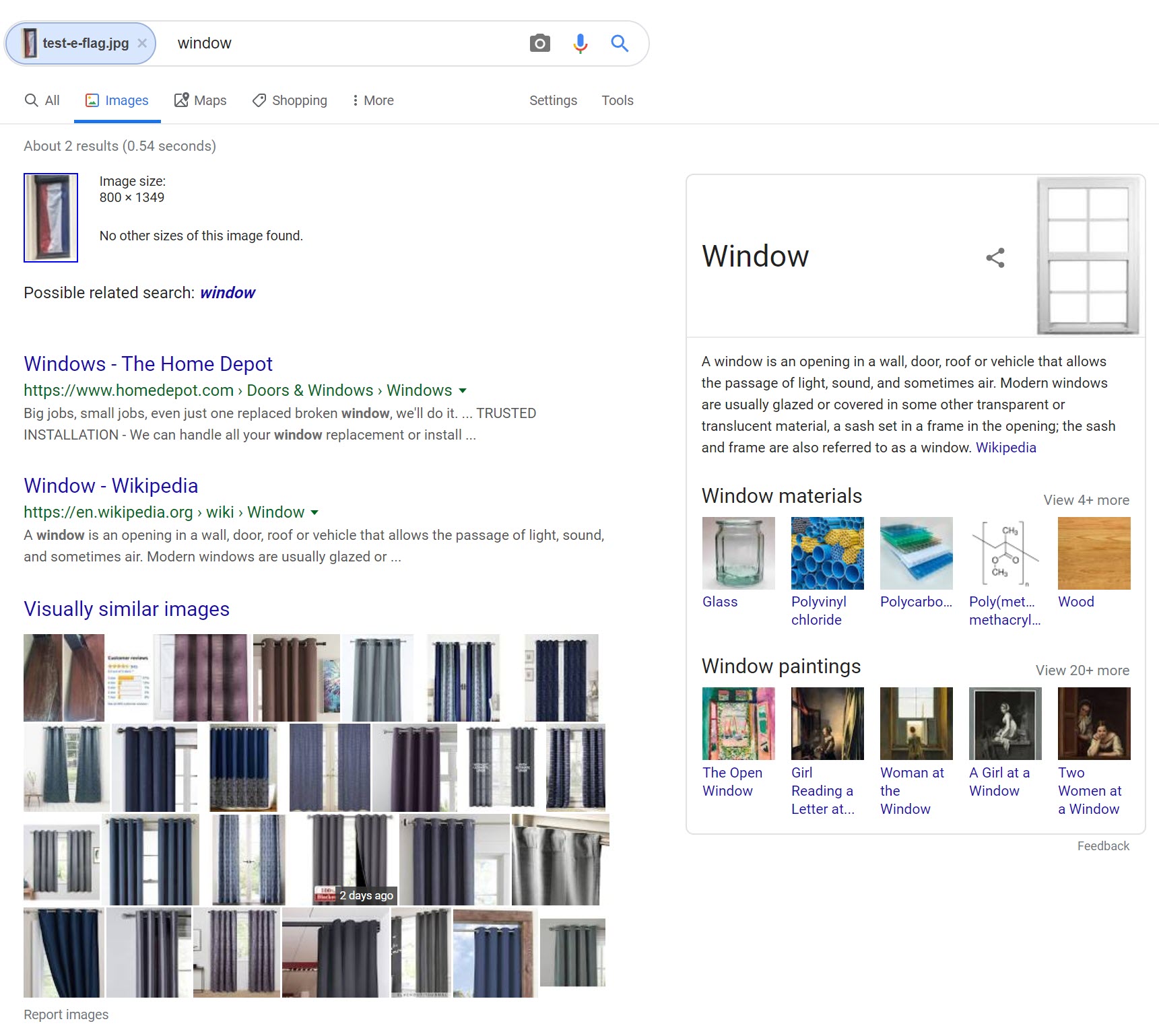
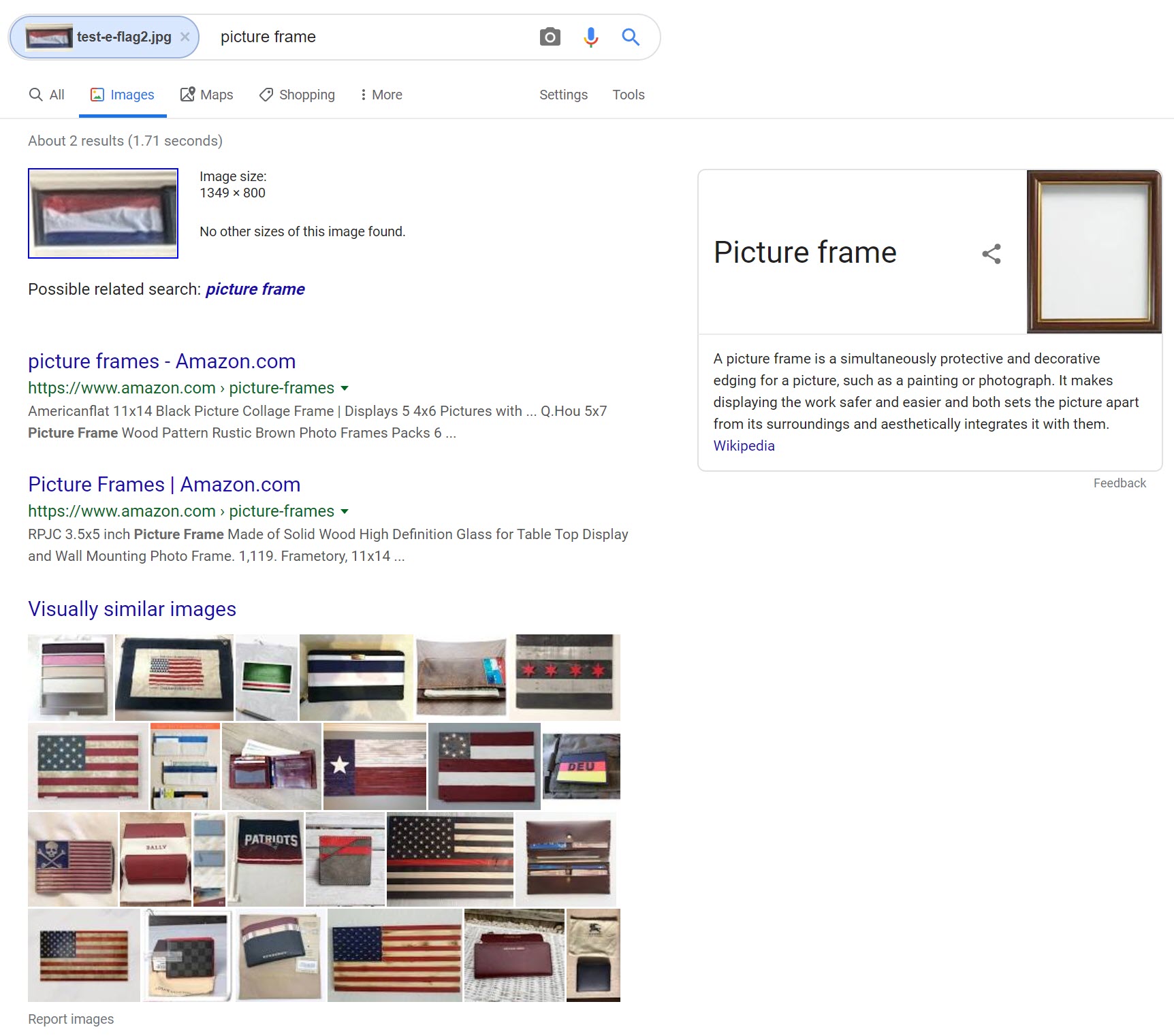
Final Scorecard: Yandex 9/14; Bing 2/14; Google 3.5/14
Creative Searching
Even with the shortcomings described in this guide, there are a handful of methods to maximize your search process and game the search algorithms.
Specialized Sites
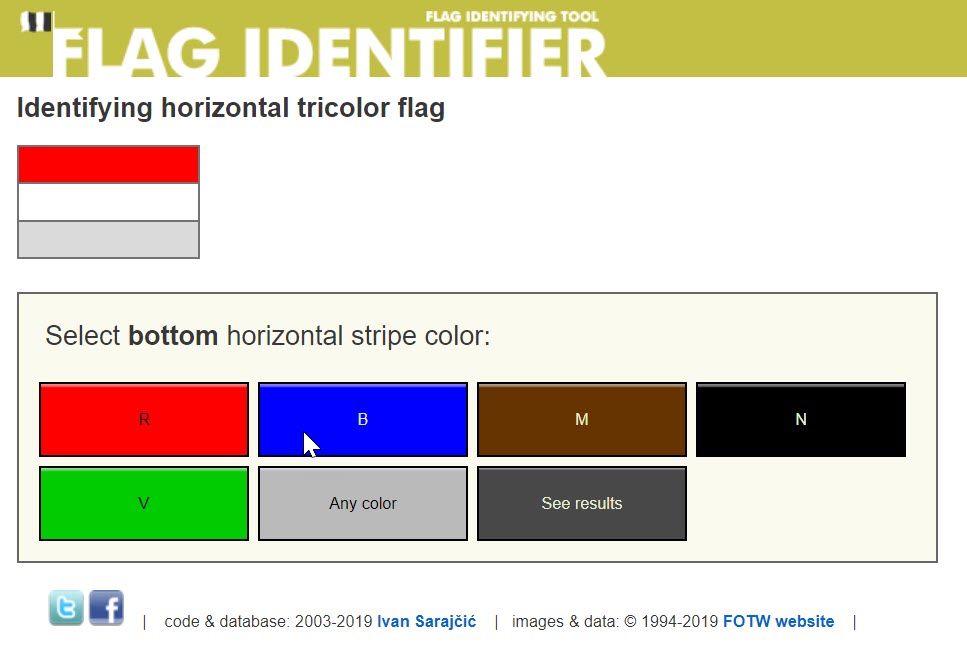
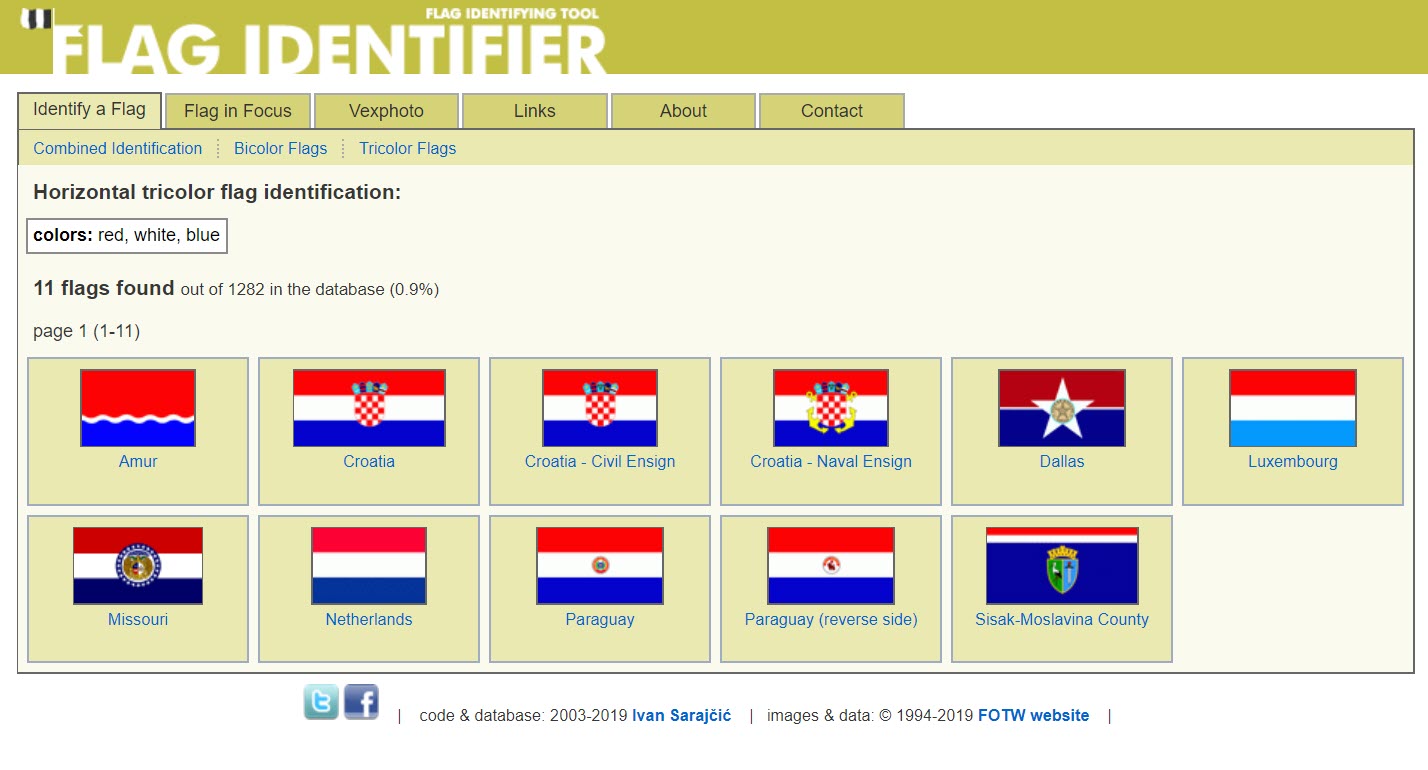
For one, you could use some other, more specialized search engines outside of the three detailed in this guide. The Cornell Lab’s Merlin Bird ID app, for example, is extremely accurate in identifying the type of birds in a photograph, or giving possible options. Additionally, though it isn’t an app and doesn’t let you reverse search a photograph, FlagID.org will let you manually enter information about a flag to figure out where it comes from. For example, with the Dutch flag that even Yandex struggled with, FlagID has no problem. After choosing a horizontal tricolor flag, we put in the colors visible in the image, then receive a series of options that include the Netherlands (along with other, similar-looking flags, such as the flag of Luxembourg).
Language Recognition
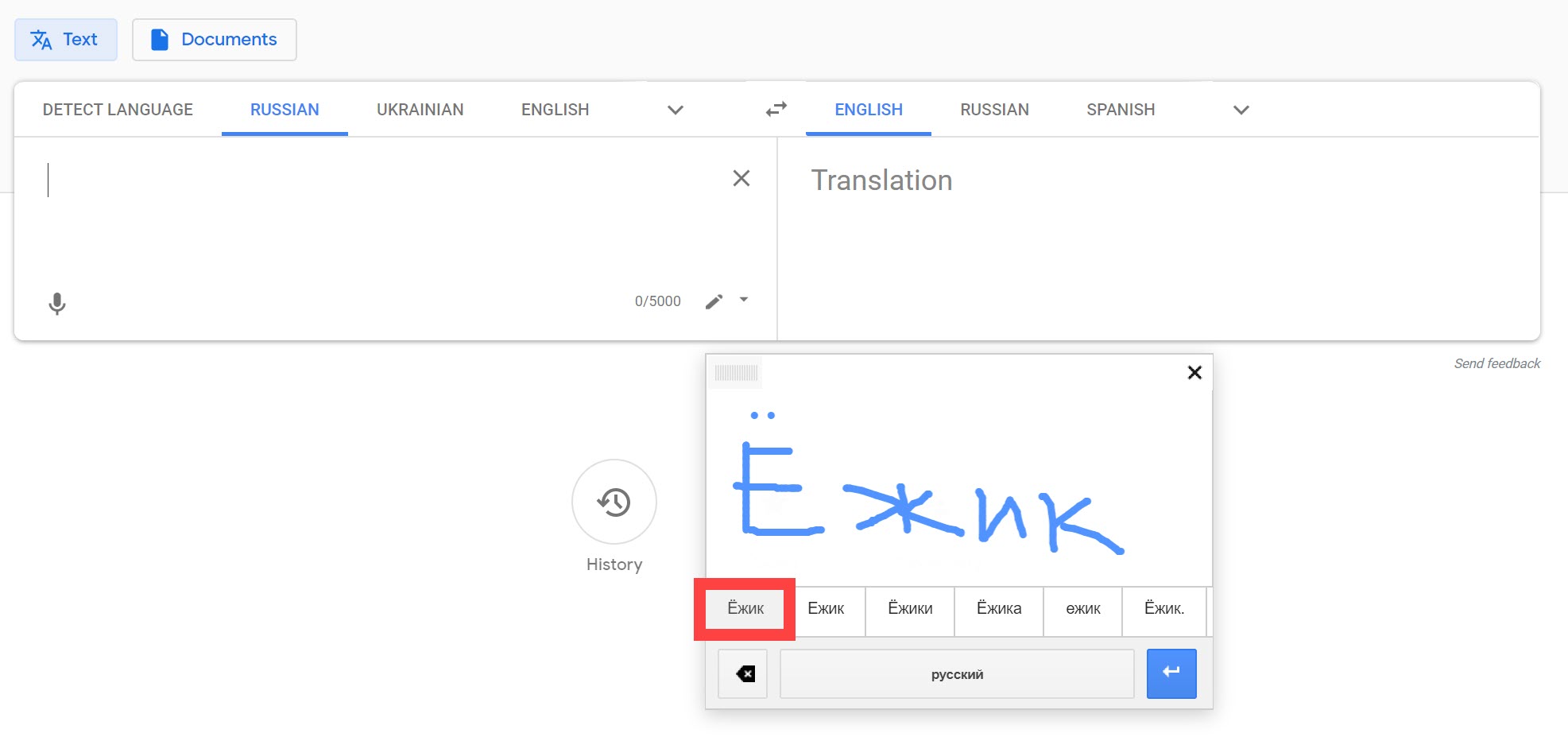
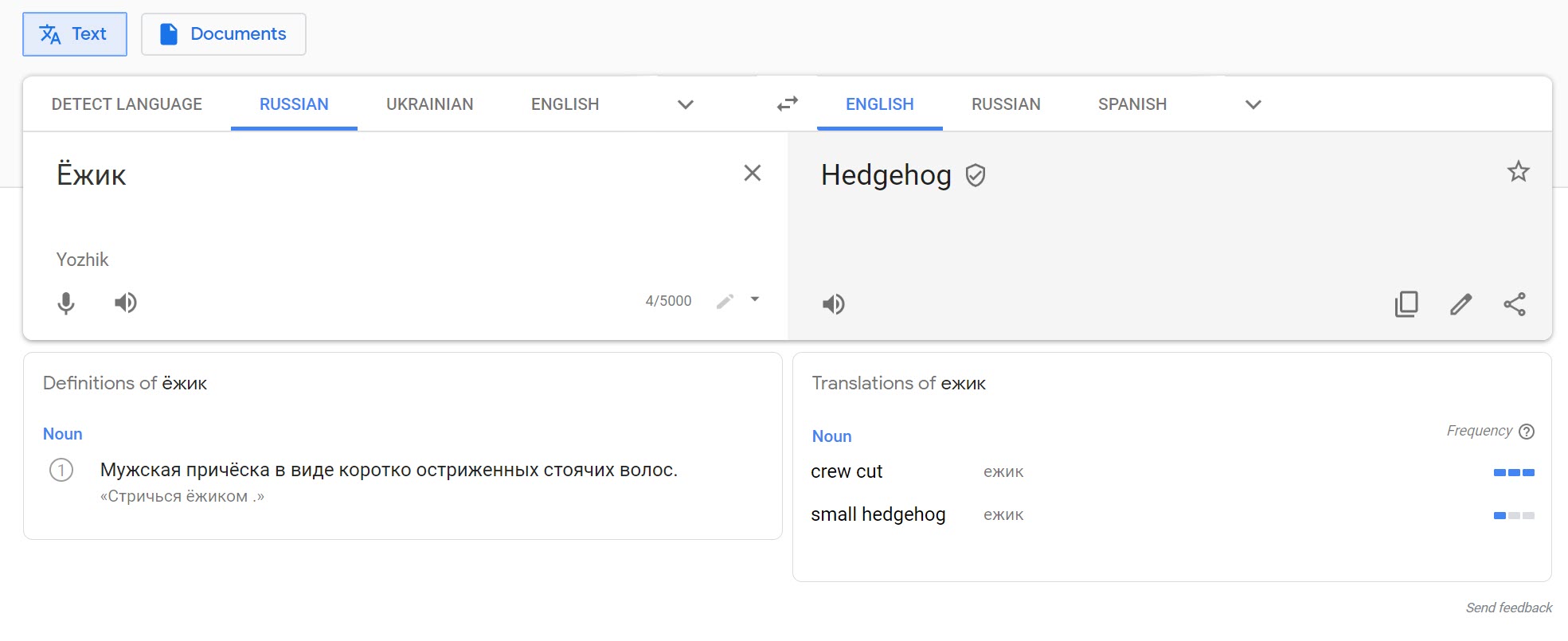
If you are looking at a foreign language with an orthography you don’t recognize, try using some OCR or Google Translate to make your life easier. You can use Google Translate’s handwriting tool to detect the language* of a letter that you hand-write, or choose a language (if you know it already) and then write it out yourself for the word. Below, the name of a cafe (“Hedgehog in the Fog“) is written out with Google Translate’s handwriting tool, giving the typed-out version of the word (Ёжик) that can be searched.
*Be warned that Google Translate is not very good at recognizing letters if you do not already know the language, though if you scroll through enough results, you can find your handwritten letter eventually.

Pixelation And Blurring
As detailed in a brief Twitter thread, you can pixelate or blur elements of a photograph in order to trick the search engine to focus squarely on the background. In this photograph of Rudy Giuliani’s spokeswoman, uploading the exact image will not bring back results showing where it was taken.
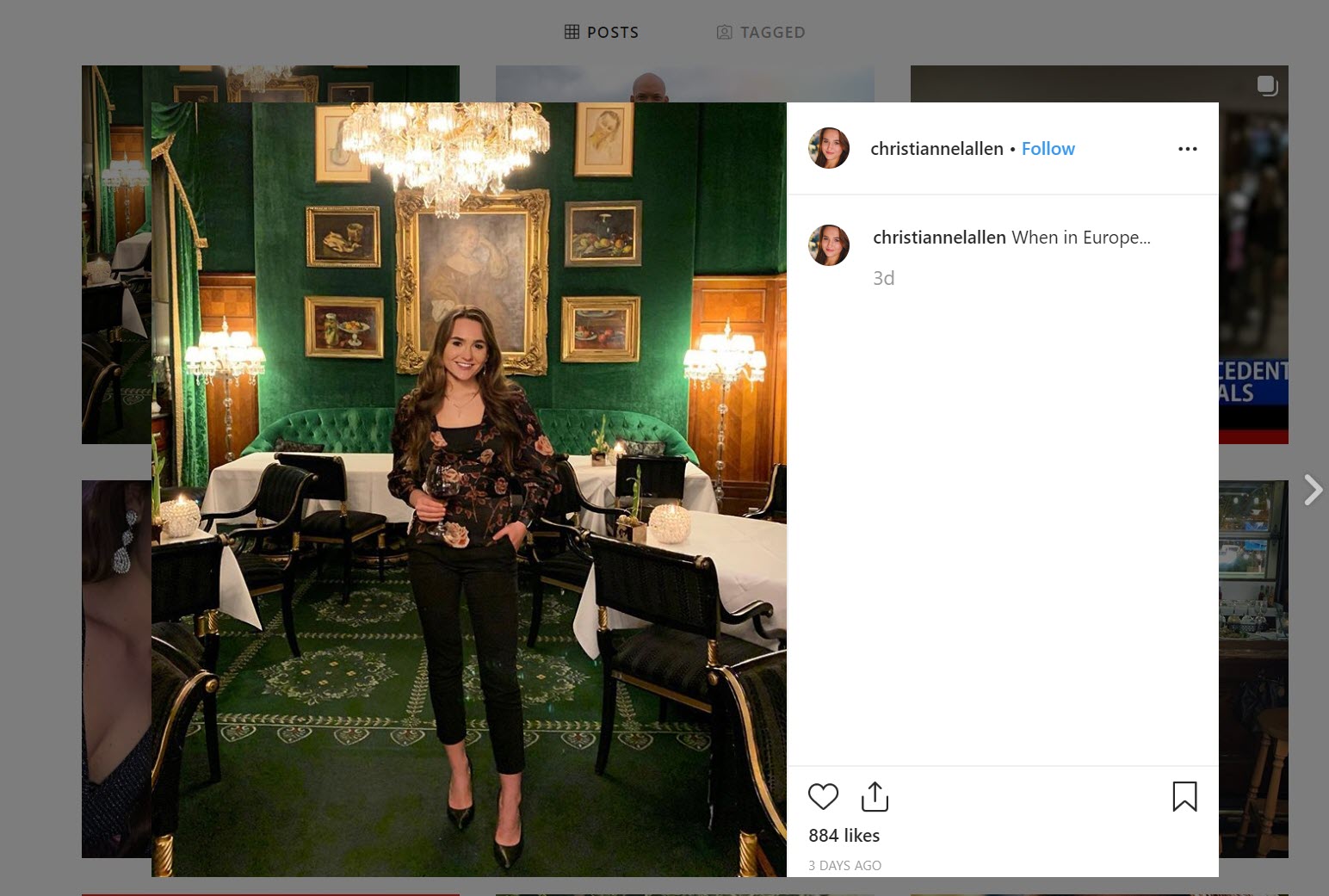
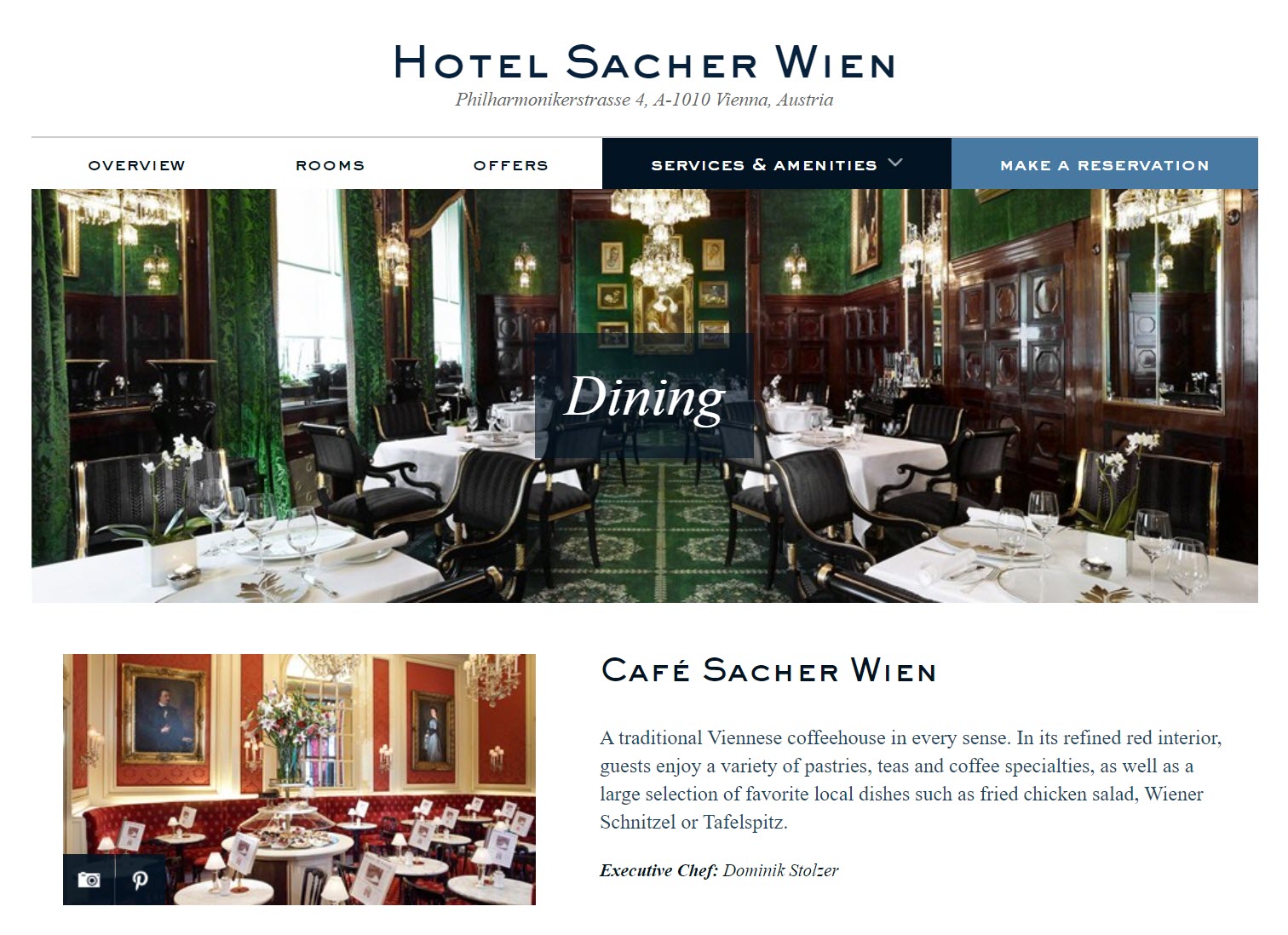
However, if we blur out/pixelate the woman in the middle of the image, it will allow Yandex (and other search engines) to work their magic in matching up all of the other elements of the image: the chairs, paintings, chandelier, rug and wall patterns, and so on.

After this pixelation is carried out, Yandex knows exactly where the image was taken: a popular hotel in Vienna.

Conclusion
Reverse image search engines have progressed dramatically over the past decade, with no end in sight. Along with the ever-growing amount of indexed material, a number of search giants have enticed their users to sign up for image hosting services, such as Google Photos, giving these search algorithms an endless amount of material for machine learning. On top of this, facial recognition AI is entering the consumer space with products like FindClone and may already be used in some search algorithms, namely with Yandex. There are no publicly available facial recognition programs that use any Western social network, such as Facebook or Instagram, but perhaps it is only a matter of time until something like this emerges, dealing a major blow to online privacy while also (at that great cost) increasing digital research functionality.
If you skipped most of the article and are just looking for the bottom line, here are some easy-to-digest tips for reverse image searching:
- Use Yandex first, second, and third, and then try Bing and Google if you still can’t find your desired result.
- If you are working with source imagery that is not from a Western or former Soviet country, then you may not have much luck. These search engines are hyper-focused on these areas, and struggle for photographs taken in South America, Central America/Caribbean, Africa, and much of Asia.
- Increase the resolution of your source image, even if it just means doubling or tripling the resolution until it’s a pixelated mess. None of these search engines can do much with an image that is under 200×200.
- Try cropping out elements of the image, or pixelating them if it trips up your results. Most of these search engines will focus on people and their faces like a heat-seeking missile, so pixelate them to focus on the background elements.
- If all else fails, get really creative: mirror your image horizontally, add some color filters, or use the clone tool on your image editor to fill in elements on your image that are disrupting searches.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![parking sign [Estacionamento]](https://017qndpynh-flywheel.netdna-ssl.com/app/uploads/2019/12/d-estacionameno.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}