
Automatically Finding Weapons in Social Media Images Part 2
Translations:
This post was originally published on the AutomatingOSINT.com blog.
In the first part of this series we examined how to write some code that can slice and dice and image and then submit it to Imagga. By examining the tags that come back we can make a fairly accurate guess as to whether there is a weapon present in the picture. Now we get to do the fun part of hunting through Twitter to try to find the images. We could build a really extensive crawler to just roam around Twitter but what I want is a more targeted tool where we can point it at an account and have it retrieve all of the photographs for that account. You can easily extend the script to go much deeper if you like (such as friends and followers), but I will leave that as homework to you the reader. Let’s get started.
Setup a Twitter API Key
This is the first thing that my students have to do when they join my course. Head over to https://apps.twitter.com (you will need a Twitter account) and setup a new application. Follow the steps below:
- Click the Create New App button.

2. Give your application a name, a brief description and a website.

3. Once your application is created click on the Keys and Access Tokens link to start the API key generation process.

4. The first thing you need to do is generation an access token. Click the Create my access token button.

5. Now you can use the Consumer Key, Consumer Secret, Access Token and Access Token Secret in the Python script that we are going to be developing.

WARNING: Do not give your keys or tokens to anyone. This can mean someone can hijack your Twitter account or perform actions on your account that you most definitely don’t want them to do. I have just kept them in place for demonstration purposes.
Ok now that we have our Twitter API key setup, let’s start coding up the second half of our image checking script. First make sure you have some important libraries installed:
pip install requests pip install requests_oauthlib
If you don’t know how to use pip yet, then watch my how-to videos or sign up for one of my free webinars.
Adding Twitter to Our Gunhunter
Open up the gunhunter.py script from the last post (source is here) and add the following three lines of code to the top of the script:

Now let’s add in our authentication pieces for Twitter. My students are going to be able to do this part by heart at this point, and are likely rolling their eyes reading this. Drop it into Line 22 or so:
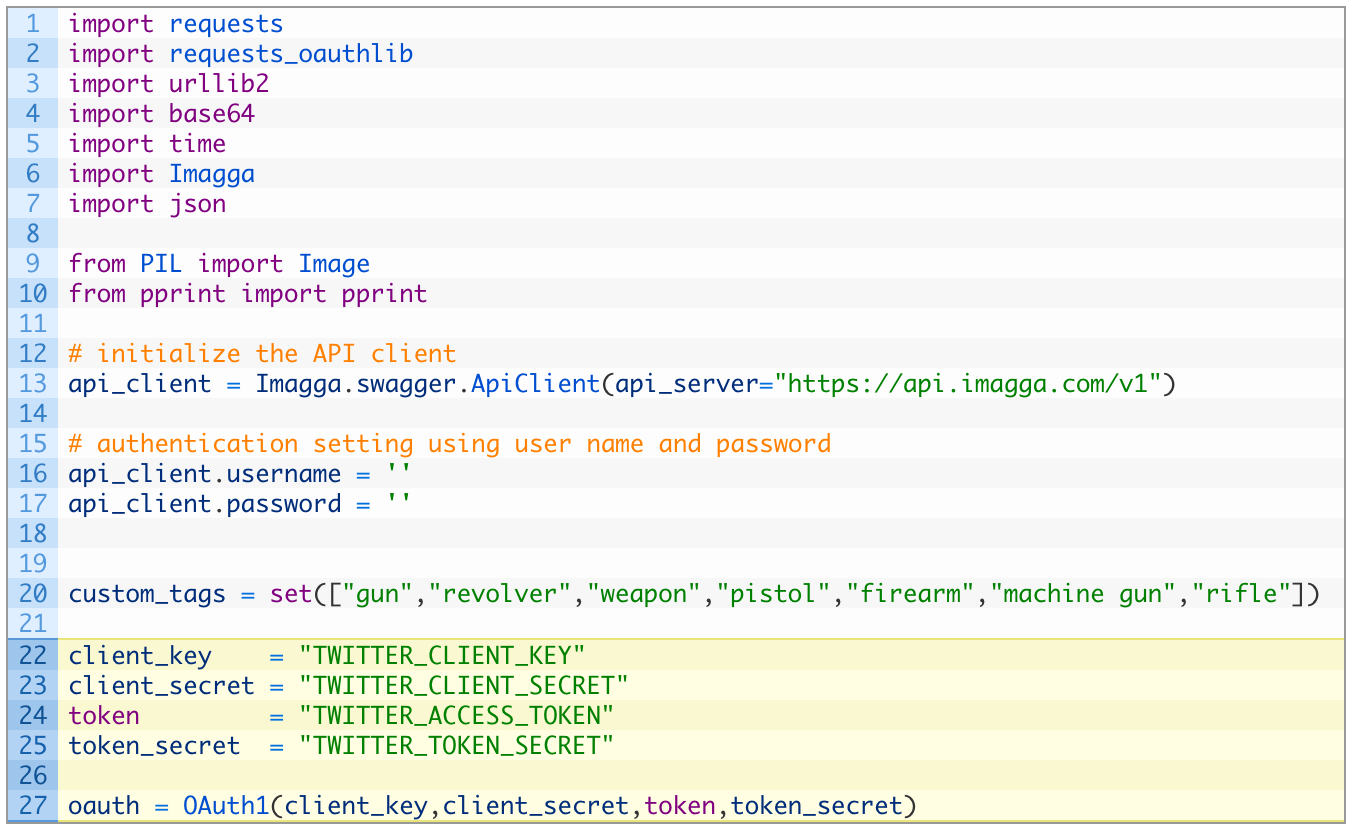
Perfect! This takes care of the pieces required to get authenticated to Twitter. On lines 22-25 make sure you copy and paste in your API credentials that we created in the previous section. Now I am literally going to defer to code taken directly from my training. Just keep adding code underneath the code you just inserted:
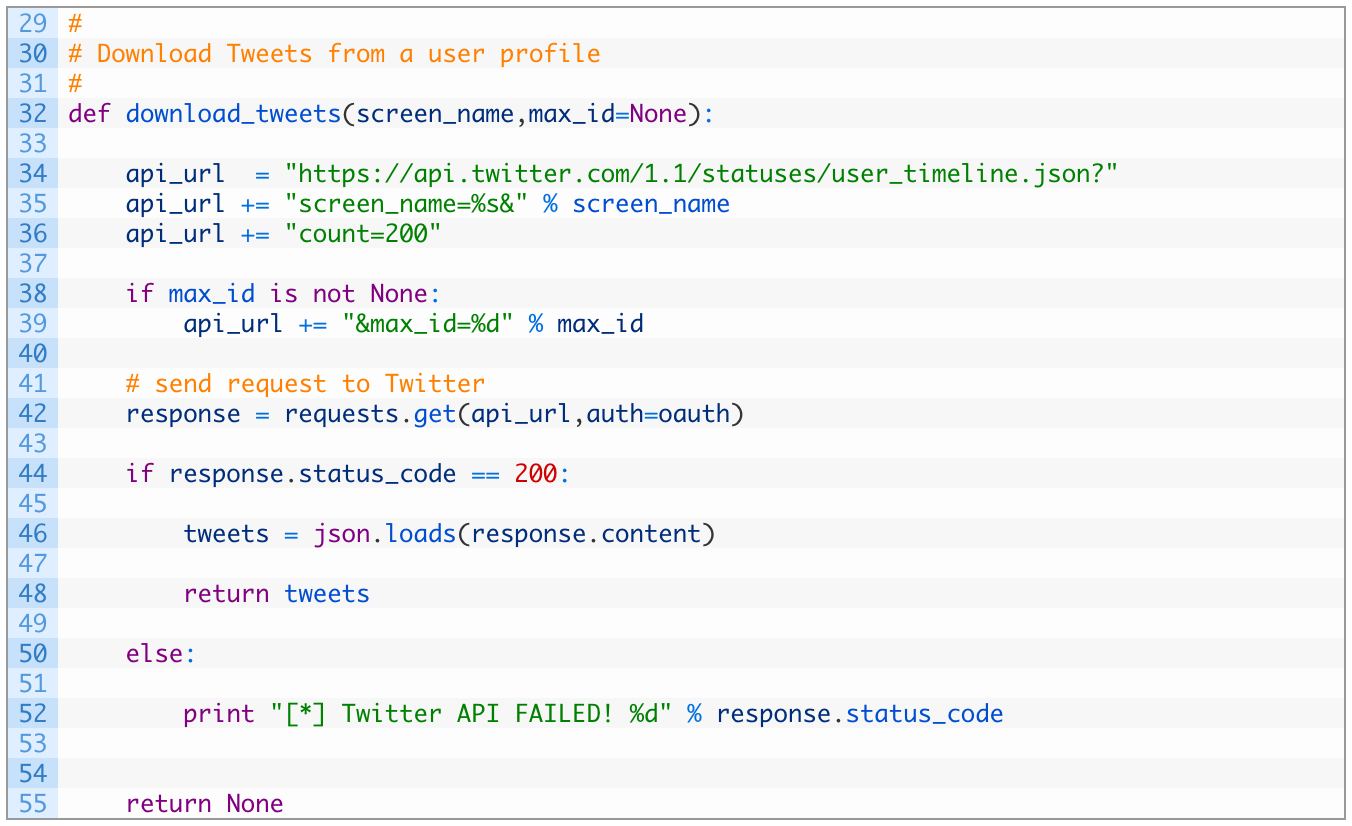
Let’s take a closer look at the code:
- Line 32: we define our download_tweets function that takes a screen name (username), and a max_id parameter. We’ll cover how the max_id parameter works later.
- Lines 34-39: we build our Twitter API url that will pass in the desired screen_name and request 200 Tweets each time the API is called.
- Line 42: we send off the request to the Twitter API.
- Lines 44-48: if we receive a response back successfully (44) we then parse the JSON (46) and return the list of Tweets back (48).
Now that we have the initial function that will retrieve Tweets, we need to implement a loop that will continually call this function to retrieve all of the Tweets in a users’s timeline. This where the max_id parameter will come into play, as we will need to “page” through results as we download 200 Tweets at a time. The maximum number of Tweets that we can retrieve from a timeline is 3,20o.
Let’s implement this loop now by adding some code underneath your previous code section:
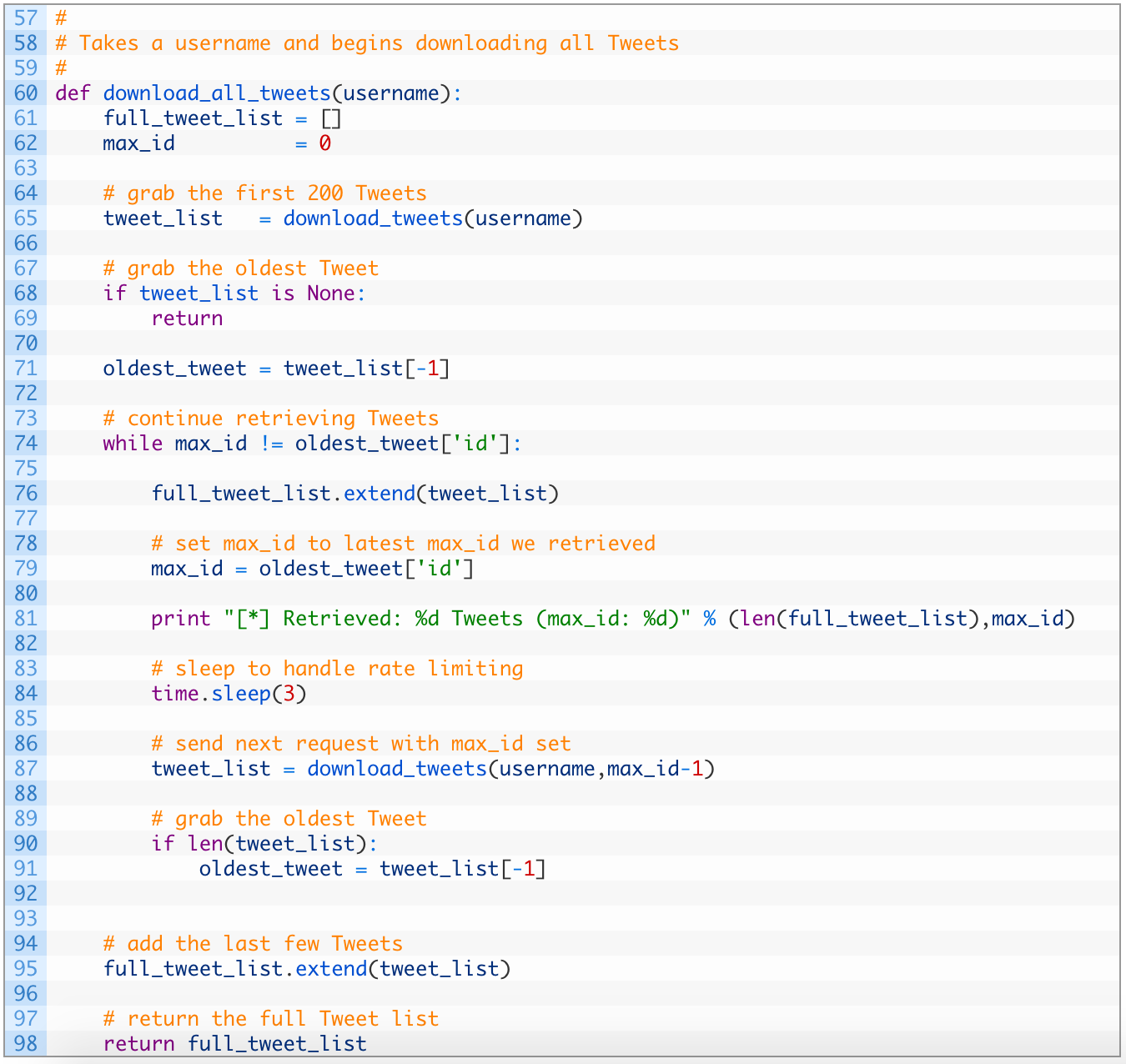
Alright this is a bit more involved. Let’s dig in:
- Line 60: we define our function download_all_tweets to receive the Twitter username (also called a screen name).
- Line 65: we do our first request for 200 Tweets for the target account.
- Line 71: we snag the last Tweet in the list so that we can use it as the maximum ID for future requests. This is how we page through results, by continually telling the Twitter API to give us Tweets that are older than the max ID we pass in.
- Line 74: we continue to make requests as long as we have older Tweets to retrieve. If we run out of Tweets or max out at 3,200 these two values will be the same and the loop will exit.
- Lines 76-84: we add the new Tweets to our full_tweet_list (76) and again grab the oldest Tweet’s ID (79). We sleep for 3 seconds (84) to make sure we aren’t violating the rate limiting on the API.
- Line 87: we run another request, this time passing in our max_id variable minus 1. This ensures that we don’t get overlap between our oldest Tweet in this list, and the newest Tweet in the next request.
- Lines 90-91: if we receive Tweets back (90) we again grab the oldest Tweet so we can examine its ID.
- Lines 95-98: we store the last set of Tweets we received from the API (95) and then return the list of Tweets.
Whew! That was a big chunk of code but it is the core of our script for retrieving Tweets. Now we need to implement some additional code that will call our download_all_tweets function, iterate over the results and find images. Let’s do this now. Drop to the very bottom of your script and add the following code:
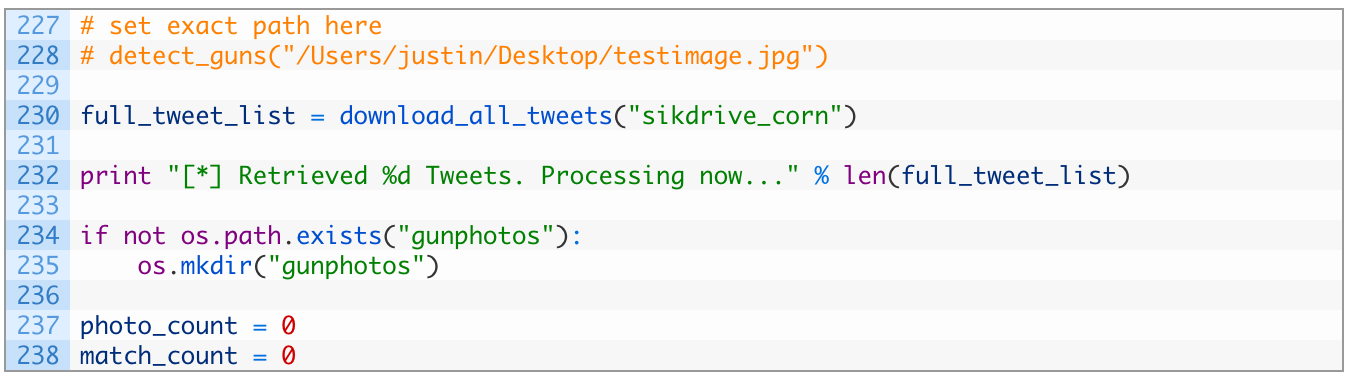
- Line 228: we are commenting out our old call to the detect_guns function as we’ll use it later on.
- Line 230: we make our initial call to download_all_tweets passing in the target account identified in the first part of this article series.
- Lines 234-235: we check if we have a gunphotos directory present (234) and if not, we create one (235). This is where we will store our matched photos.
Now let’s add in the logic that will handle walking through the list of Tweets, and downloading photos. Continue to add code to your script:
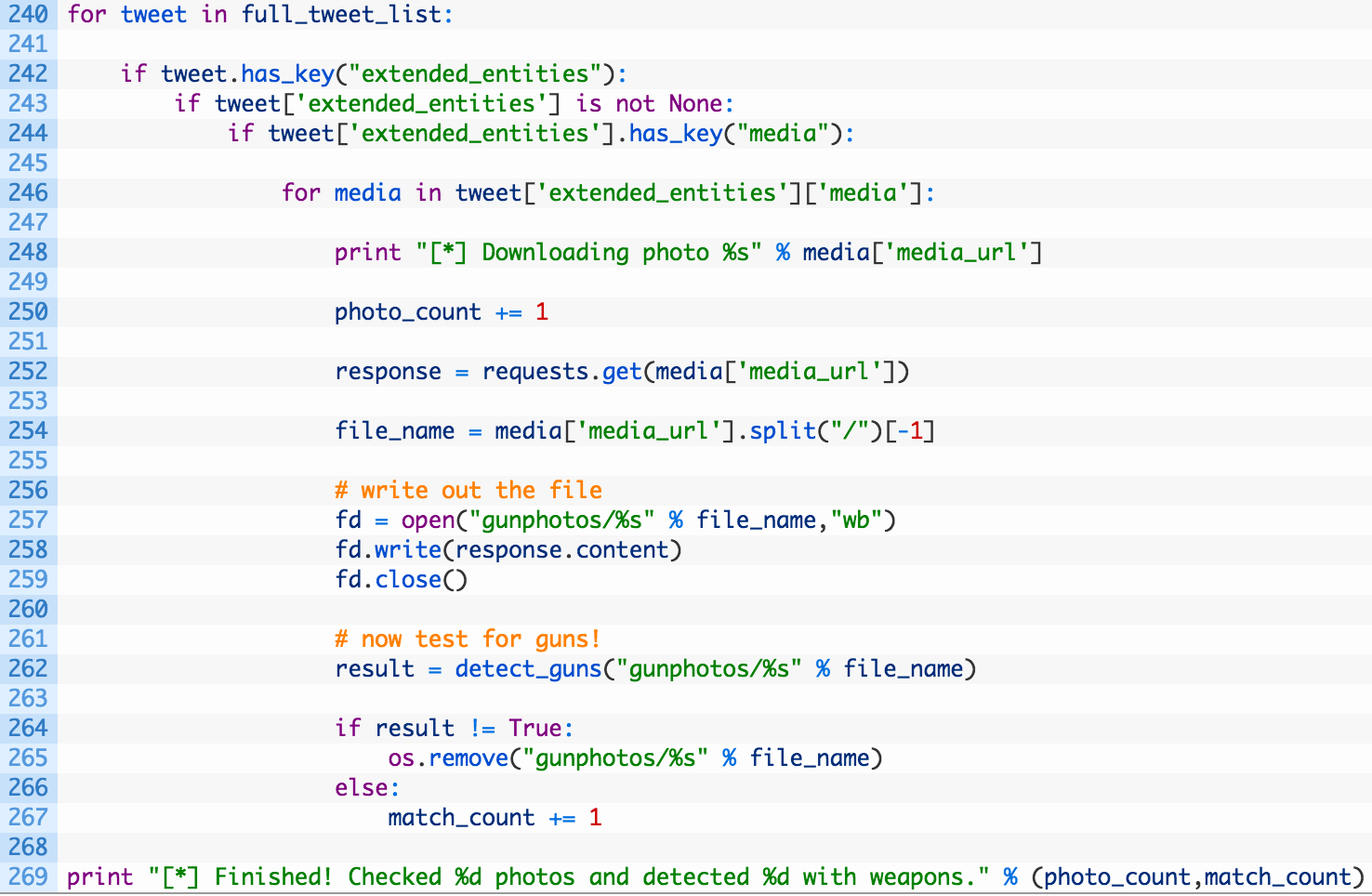
This is a big whack of code so let’s have a closer look:
- Lines 240-244: we walk through the list of Tweets (240) and check if we have embedded media in the Tweet.
- Line 246: we then loop over all of the pieces of media that are attached to the Tweet.
- Lines 252-254: we make a request for the photo itself (252) and then extract the filename (254) once we have successfully downloaded it.
- Lines 257-259: we store the photo on disk.
- Line 262: we now ship the photo off for Imagga tagging, using our previously developed detect_guns function.
- Lines 264-267: if we did not detect a weapon (264) we remove the file from disk (265).
Ok, the bulk of our work is complete. However, there are some small modifications that we need to do from the previous article’s script to make it compatible with our current script. Make the following changes:
- Line 179: return result
- Line 201: return result
- Line 202: (only a single tab indent) return False
- Line 220: (need to add this line) return result
- Line 225: (need to add this line) return True
This allows for us to determine whether an image matches or not so that we can either keep or delete a photo. Now for the fun part!
Let it Rip!
Give the file a run and you should start to see some output:
[*] Retrieved: 196 Tweets (max_id: 650698997825454080)
[*] Retrieved: 395 Tweets (max_id: 644891106040225792)
[*] Retrieved: 595 Tweets (max_id: 640693840710619136)
[*] Retrieved: 795 Tweets (max_id: 639060938038095872)
[*] Retrieved: 991 Tweets (max_id: 637632592041385984)
[*] Retrieved: 1188 Tweets (max_id: 634017684871446529)
[*] Retrieved: 1384 Tweets (max_id: 632545008122335232)
[*] Retrieved: 1581 Tweets (max_id: 630016456759971840)
[*] Retrieved: 1781 Tweets (max_id: 627383162620899328)
[*] Retrieved: 1977 Tweets (max_id: 621349791230877696)
[*] Retrieved: 2174 Tweets (max_id: 613701000856113152)
[*] Retrieved: 2370 Tweets (max_id: 607216480158138369)
[*] Retrieved: 2569 Tweets (max_id: 591970334611349504)
[*] Retrieved: 2763 Tweets (max_id: 588807104091148288)
[*] Retrieved: 2962 Tweets (max_id: 584001699926286339)
[*] Retrieved: 3158 Tweets (max_id: 581492361026408448)
[*] Retrieved: 3199 Tweets (max_id: 581463105890185218)
[*] Retrieved 3199 Tweets. Processing now…
[*] Downloading photo https://pbs.twimg.com/ext_tw_video_thumb/652593985240846336/pu/img/yoSKGsdoBrcM1MpX.jpg
[*] Trying image gunphotos/yoSKGsdoBrcM1MpX.jpg
…..
[*] Trying image gunphotos/3k0mIn4EnNvkRG7a.jpg
[*] Image matches! => weapon
…
[*] Finished! Checked 64 photos and detected 2 with weapons.
Awesome, so you can see the script retrieve all of the user’s Tweets, and then begin systematically working through each image (including preview images for videos) to test which ones have weapons. You can now go check the gunphotos directory and see the results. Well done!
You can of course now test some other accounts, or take a look at how to expand the script using the Twitter API.

