Automatically Reverse Image Search YouTube Videos
Translations:
This post originally appeared on the AutomatingOSINT.com blog.
Eliot Higgins had an excellent post where he shows how to grab preview images from YouTube videos and use them for verification, or potentially to find additional sites where that video might be shown or linked to. This technique is called reverse image searching which I have covered here on this blog as well. This OSINT technique is incredibly powerful because it can potentially give you additional sites you can view to see who is using a particular video, or it can also tell you whether someone is lying about when an original video was made. What we would like to do at this point is automate this process by using the YouTube API and the TinEye API (paid). The goal of this exercise is to develop a script where we can just input a YouTube video ID and have our script retrieve the video thumbnails and submit them to TinEye for a reverse image search. The goal here is to speed up the process of doing this verification.
YouTube API – Retrieve Preview Photos
The YouTube API is wonderful for both searching for videos and for pulling lots of metadata out of the video records themselves (I teach it in my course). We are going to utilize the API to retrieve the thumbnails for a particular video and then we will pass these thumbnails off to the TinEye API to perform the reverse image search for us. First things first, make sure you go get yourself a YouTube API key here. Additionally there is a known URL format that will give you additional video preview images. We will build this URL format in our script as well so that we get the best coverage possible.
TinEye API
The folks at TinEye have been most gracious and created a Python library for communicating with their commercial API. You can grab it from here and the documentation is here. Make sure you follow their instructions for installying their Python library.
Coding It Up
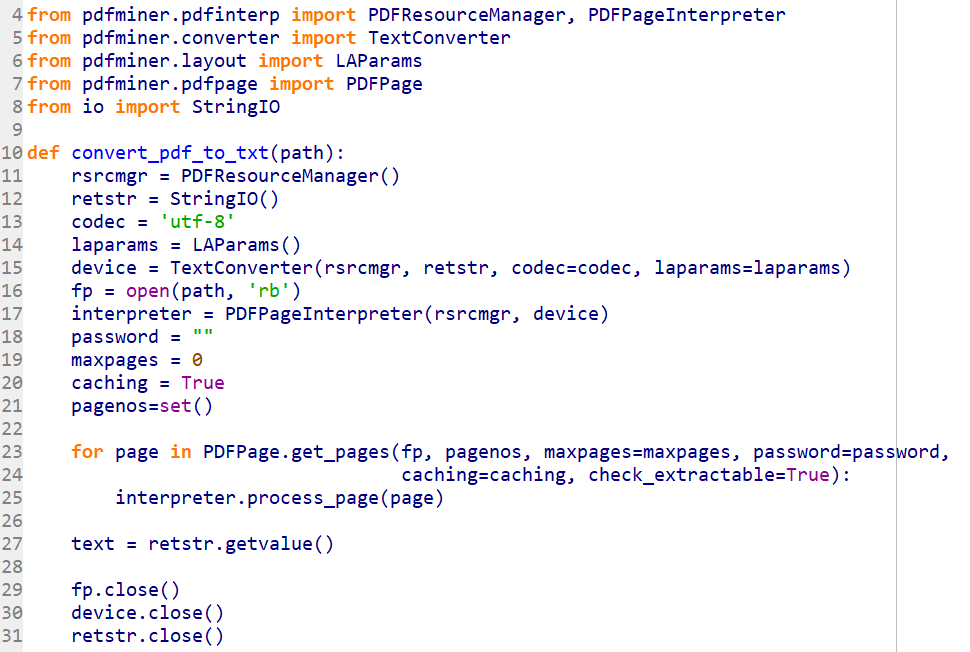
Alright let’s get those coding fingers warmed up and open a new file called bellingcatyoutube.py. Start punching in the following code (you can download the source code from here):

Here we are just pulling in the necessary libraries, initializing the TinEye API and adding some command line argument parsing. Nothing too fancy yet. Let’s now put in the plumbing for our YouTube API call:

Ok let’s dissect this a bit more:
- Line 20: we are defining our youtube_video_details function to take in a video ID.
- Lines 22-24: we are constructing our YouTube API request URL by passing in the video ID and our YouTube API key.
- Line 26: send the request off to the magical Google servers.
- Lines 28-32: if we get a good response back (28), we parse the JSON (30) and return the results of our query (32).
Perfect, this function will be used to grab the default thumbnails that are associated to every YouTube video. Now we are going to use this function to build up a list of image URLs that we can pass to TinEye. Let’s add this code now:
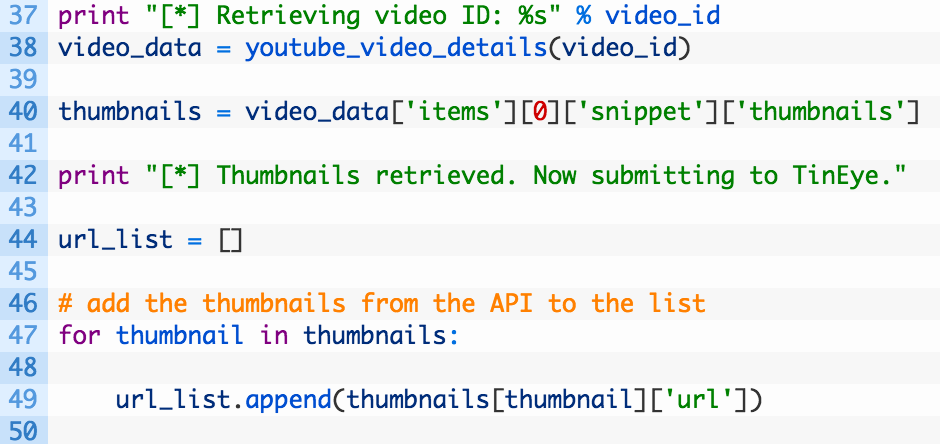
- Line 38: we use our previously developed function to retrieve all data associated to a particular video (Note: you can explore the video_data variable and see all the cool metadata attached to each video).
- Line 40: we extract the list of thumbnails from the result.
- Lines 47-49: here we are looping over each thumbnail (47) and adding it to a master list of URLs (49). We will be using this master list later on.
Now there’s a well-known yet undocumented trick with YouTube videos that allows us to grab additional preview images for the video we are interested in. This is just simply taking a known path on the YouTube servers, along with the video ID and requesting a sequential list of images. Add the following code which achieves this:
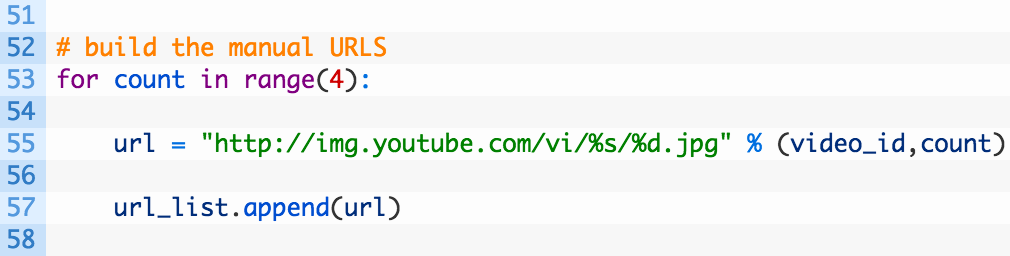
Pretty straightforward, we simply run the loop counting from 0 through 3 and build a URL using the counter and the video ID that we passed in to the script. So this would generate a list like:
https://img.youtube.com/vi/zGM47VtGQ-4/0.jpg
https://img.youtube.com/vi/zGM47VtGQ-4/1.jpg
https://img.youtube.com/vi/zGM47VtGQ-4/2.jpg
https://img.youtube.com/vi/zGM47VtGQ-4/3.jpg
Cool right? Now we are going to loop over each of the URLs and submit it to the TinEye API. Hammer out the following code:
Alright, let’s break it down a little:
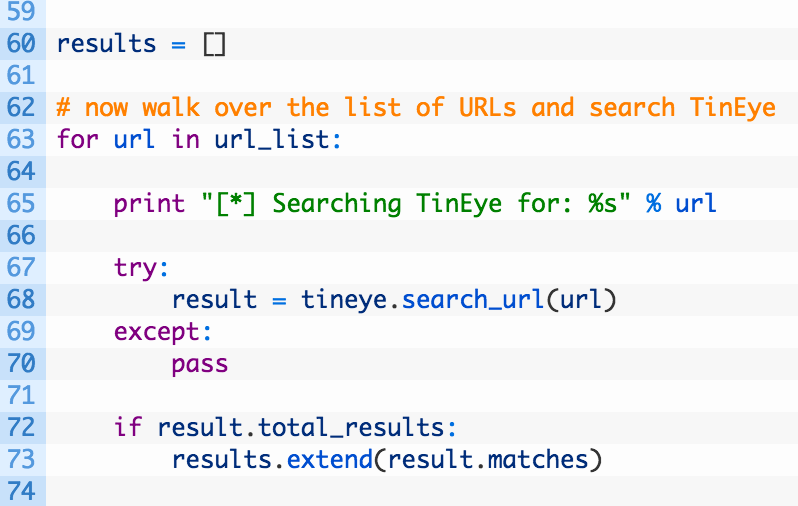
- Line 60: we initialize a results list where we will store all of the matches coming back from TinEye.
- Lines 63-73: we loop over our list of URLs (63) and then submit the URL to the TinEye API using the search_url function (68). If we detect there are matches (72) we add each of the matches to our results list (73).
Beautiful, at this point we should have a list of TinEye Match objects that contain the information about our search results. Now let’s pick that object apart and extract the important pieces of information, namely the URL of any matching sites that use the image as well as the date that TinEye crawled it. Almost there folks, a little more code to go!
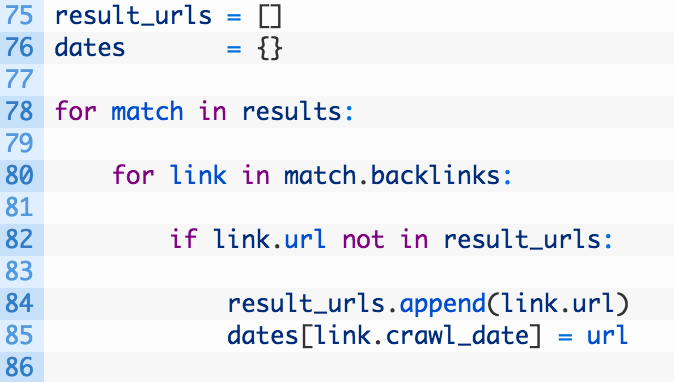
- Lines 75-76: we initialize our result_urls list (75) to store any URLs that were found in the TinEye index and a dates dictionary that will hold URLs that are keyed by date so that we can sort them and determine the oldest URL that contained our matching images.
- Lines 78-85: we loop over each of our matches (78) and then begin looping over each link contained in the TinEye Match object (80). We test if we have already captured the URL (82) and if we haven’t we store the URL (84) and the date it was retrieved (85).
Ok the heavy lifting is complete! Now we just need to print out our results and we’re done! Let’s add the final piece of code:

Pretty straightforward stuff here. We are just looping over all of the discovered URLs and printing them each out (NOTE: you could then pass all of these URLs to other scripts we have developed like the Google Analytics one or the Common Crawl one too!). Then we find the oldest crawl date by sorting the dates and using the oldest date as a key into our dates dictionary. Boom!
Let It Rip!
Sadly, the video that Eliot used in his example actually is not found in the TinEye index, however, a friend Joseph Ovid Adams had sent me a video of a rocket being fired from the ground in Syria in 2014 so I tested that. The video was at:
www.youtube.com/watch?v=zGM47VtGQ-4
So the ID of the video we want to use is: zGM47VtGQ-4
justin$:> python bellingcatyoutube.py -v zGM47VtGQ-4
[*] Retrieving video ID: zGM47VtGQ-4
[*] Thumbnails retrieved. Now submitting to TinEye.
[*] Searching TinEye for: https://i.ytimg.com/vi/zGM47VtGQ-4/default.jpg
[*] Searching TinEye for: https://i.ytimg.com/vi/zGM47VtGQ-4/hqdefault.jpg
[*] Searching TinEye for: https://i.ytimg.com/vi/zGM47VtGQ-4/mqdefault.jpg
[*] Searching TinEye for: https://i.ytimg.com/vi/zGM47VtGQ-4/maxresdefault.jpg
[*] Searching TinEye for: https://i.ytimg.com/vi/zGM47VtGQ-4/sddefault.jpg
[*] Searching TinEye for: https://img.youtube.com/vi/zGM47VtGQ-4/0.jpg
[*] Searching TinEye for: https://img.youtube.com/vi/zGM47VtGQ-4/1.jpg
[*] Searching TinEye for: https://img.youtube.com/vi/zGM47VtGQ-4/2.jpg
[*] Searching TinEye for: https://img.youtube.com/vi/zGM47VtGQ-4/3.jpg
[*] Discovered 725 unique URLs with image matches.
http://nnm.me/blogs/Y2k_live/chto-mogut-protivopostavit-boeviki-igil-rossiyskim-samoletam/
http://edition.cnn.com/2014/11/12/world/meast/syria-isis-child-fighter/index.html
http://www.cnn.com/2014/11/12/world/meast/syria-isis-child-fighter/index.html
http://www.aktuel.com.tr/multimedya/galeri/gundem/isid-2-adet-helikopter-dusurdu?albumId=67897&page=8&tc=12
http://www.cnn.com/2014/11/14/world/meast/isis-setbacks-iraq-lister/
http://www.tinmoi.vn/thach-thuc-tag.html
http://www.abc.net.au/news/2015-11-20/two-australians-accused-of-being-part-of-terrorist-kuwait-plot/6957330
http://finance.chinanews.com/stock/2013/10-11/5364352.shtml
….
[*] Oldest match was crawled on 2014-10-10 00:00:00 at http://finance.chinanews.com/stock/2013/11-15/5508881.shtml
Awesome, so now you potentially have a number of websites that you can go and investigate. The oldest crawl date is really important if you are trying to validate whether you are watching current footage or old footage. Your mileage may vary with the TinEye index, so for some of the trickier ones you can look at how Eliot does it in his post, which uses the Google reverse search mechanism.