Creating Your Own Citizen Database
A Case Study, Featuring the Electoral Roll of the Kyrgyz Republic
When conducting digital investigations, using the tools already made available by the government can be a real help. Let’s use Kyrgyzstan as an example here.
You may be looking for a witness or even a suspect in a crime, but you only know the name and approximate age. If the person has voted at the presidential elections in the Kyrgyz Republic (Kyrgyzstan), the information from the electoral roll will significantly reduce the scope of your search. In addition, you will be able to identify his/her relatives as well as the area of a city or village in which the person lived during the election time. Another interesting application: you can identify the relatives of officials, to further check whether any of them have great suspicious wealth.
The following article will demonstrate how to create such a database with a Python script (an important detail!) and use it for investigative purposes.
There are a couple of thousand PDF files of the electoral roll containing voters’ full names, dates of birth, territorial and district commissions on the website of the Central Commission for Elections and Referendums of the Kyrgyz Republic. For example, I found myself in one of these documents, at number 11 (by the way, the files look like this):
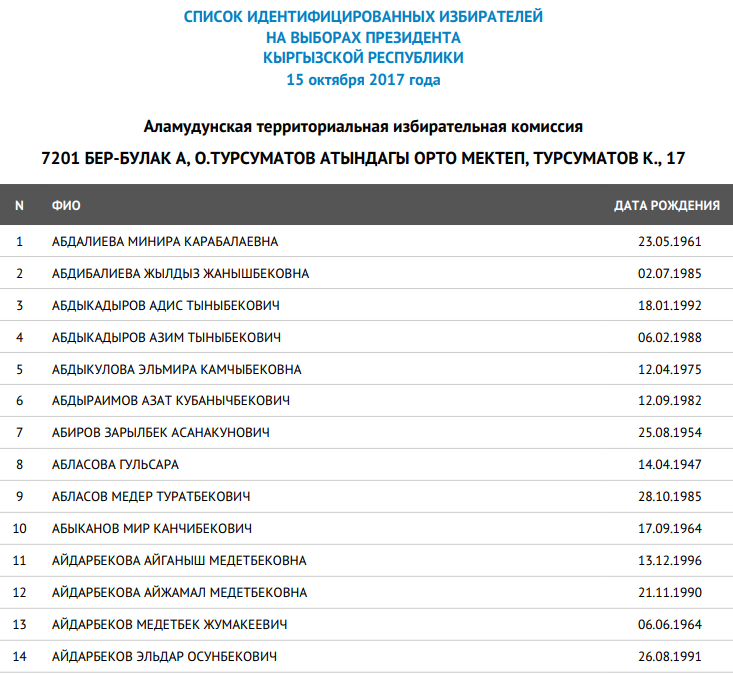
That is, provided that you know my full name, you can find out my date of birth, where I live, my relatives who have also voted and whom I live with, as well as my location on October 15, 2017.
However, if you are looking for a person knowing only their partial name and an approximate age, it would be very useful to have all available voter lists in a database where you can set the search terms.
That is exactly what we are going to do!
Steps:
- Download all the files with voter lists from the website (selenium)
- Scrape the data from the PDF (pdfminer.six) and create a database (pandas)
- Create functions which will help us easily find the information that we need.
Step 0: Don’t forget to install these before you begin!
The following libraries need to be installed:
selenium
pdfminer.six
pandas
I will use Firefox, since, to my knowledge, it is easier to configure the work with PDFs on it. In order to automate Firefox, we are going to need a driver: download it here and add it to your PATH.
Step 1: Downloading the files!

Import the required libraries and select the files where you want to save the downloads.

Configure the browser settings so that when you click on the PDF link, the file is downloaded without a download request and without a folder preview.

Run the browser with the already configured setting and go to the website. The entire link did not fit on the image, so here it what it looks like:
browser.get(“https://shailoo.gov.kg/ru/vybory-prezidenta-kr-2017_/spiski-izbiratelej-prinyavshih-uchastie-na-vyborah-prezidenta-kyrgyzskoj-respubliki/”)
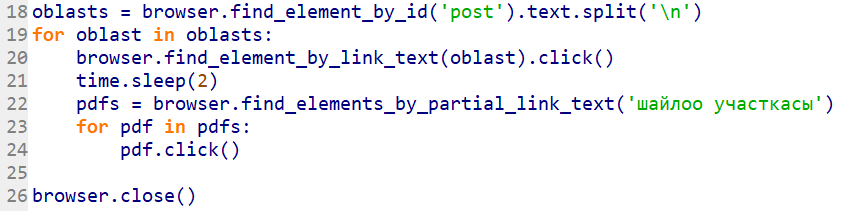
Line 18: The links are split into regions of the Kyrgyz Republic on the website; therefore, we first look for the names of all regions.
Lines 19-24: Create an iteration:
Find the link by the name of the region; go to the link (line 20),
Wait for 2 seconds for the page to load (line 21),
The names of all links in the PDF have the words “шайлоо участкасы” in them (which translates into “polling station”). Look for all of them (line 22),
Click on each link individually (lines 23-24), and since we have already set up automatic PDF downloads, clicking is enough to download the files.
Line 26: Everything is downloaded – close the browser!
Step 3: Extracting data and creating a database
More than two thousand files are now downloaded and ready for scraping. However, if we sort them by size, we’ll see that some of them do not contain any data and weigh nothing. These files shall be deleted immediately. Let’s start!
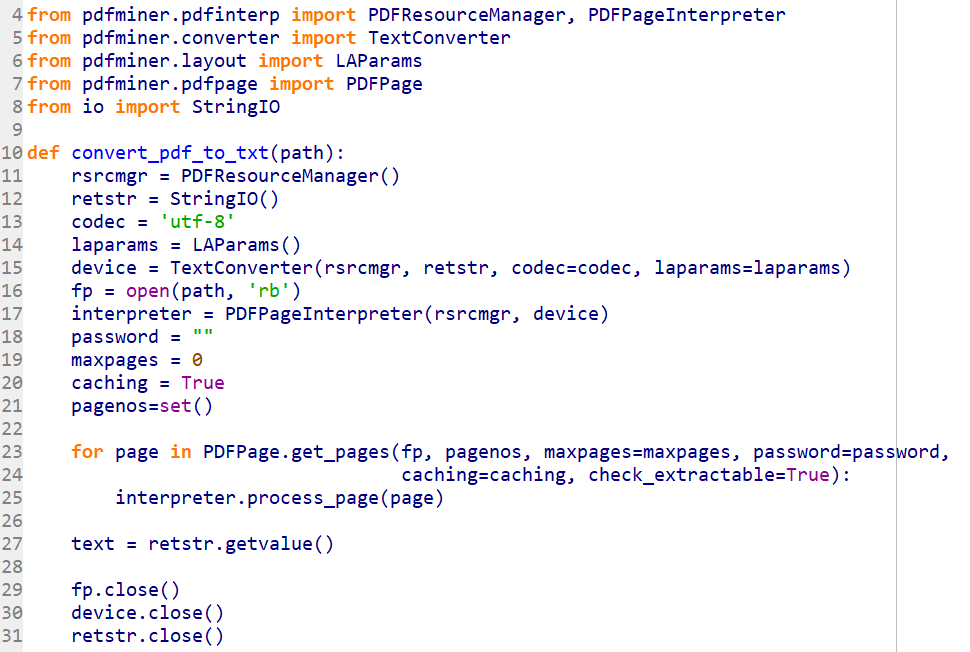
We will need a function that will convert our PDF into a text format. That’s not my strongest suit, therefore I copied this huge piece from stackoverflow. I can vouch that it works perfect.
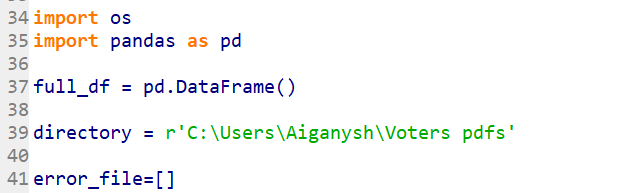
Line 34-39: Import more libraries; create an empty dataframe (where we will load the data from each file); set the directory where all downloaded files are stored;
Line 41: Empty sheet. In case the required data from the file was not downloaded successfully, the sheet will save the file name so that we have a chance to come back to it later.
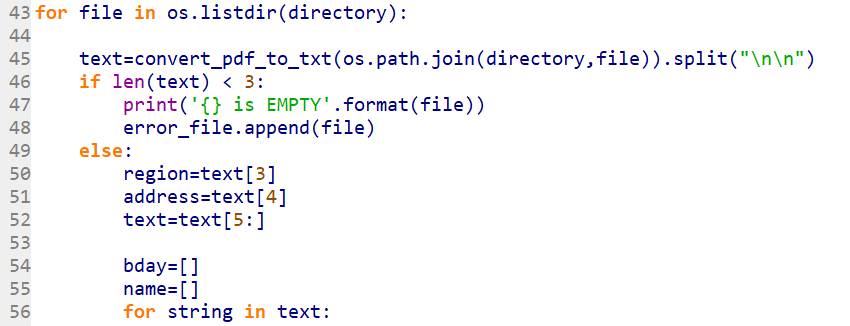
Extracting the necessary data
Line 43: Start the iteration for each file in the folder.
Line 45: Convert PDF into text format (one big list).
Lines 46-48: Occasionally, downloaded files won’t contain the electoral roll, but only 2 elements that we do not need. If that’s the case, the file will be displayed as empty. Attach its name to the error list and skip it.
Lines 49-55: Otherwise, find the data by territory and address of a polling station, delete the first five elements. Create empty sheets for full name and date of birth.

Wrangling the data!
Lines 57-59: Birth dates are recorded in dd.mm.yyyy format. Therefore, if an element contains a dot and the number of its characters is equal to 10, then the element is a birth date.
Lines 60-62: Later it turned out, that a few full names contain dots. Therefore, if the element’s length is not equal to 10, but there is a dot, than it goes into ‘Full names’ list.
Lines 63-66: We don’t need these elements, so we skip them.
Lines 67-68: If the element does not meet the above mentioned requirements, than it is definitely a full name and it adds to the list of the same name.

Once you have extracted all required data from the text, proceed to creating a dataframe.
Lines 70-73: Check whether the number of names corresponds to the number of birth dates (there is a birth date for each name). If so, then everything is correct and we can create a table with the following columns: name, birth date, territorial and district electoral commissions. Attach the table to the full-table, aka the database. Display on the screen, that the data has been scraped.
Lines 70-74: If the numbers did not match, then there’s been an error. Display it and add the file name to the error list.
![]()
Once the data from all files are merged into one database, save them as a pickle to be able to quickly download the data, when necessary.
A database of more than one and a half million citizens of the Kyrgyz Republic is ready (the population is about 6 million people)!
Step 3: Database search
I’m going to switch to Jupyter as it displays much more attractive search results.
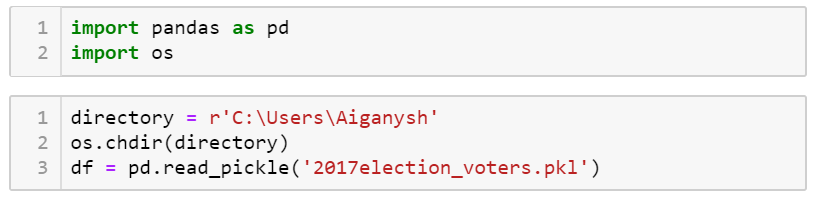
I am importing the libraries and locating the previously saved pickle.

Then we create functions to facilitate the search process. The first one, via the partial name. The second one, via the partial date of birth. And the third one is a complex function.
Searching!
Let’s assume you know my first name and that I was born in December 1996 – enter the data.
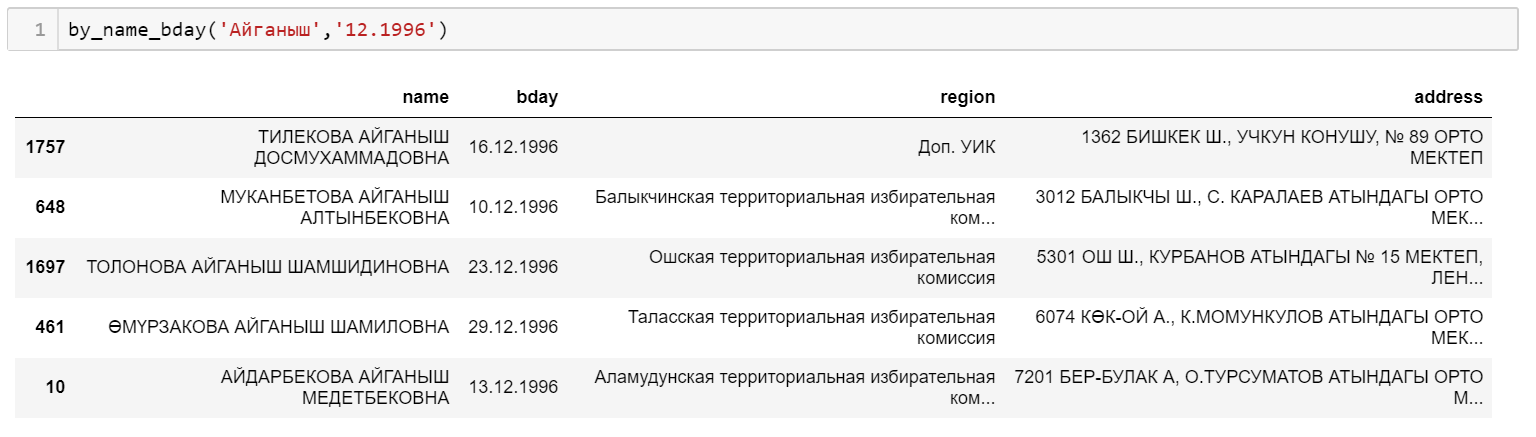
And the list of 1.6 million has now been reduced to 5. Done!

