
Using the Wayback Machine and Google Analytics to Uncover Disinformation Networks
Google Analytics is a popular service for tracking and analysing traffic to a website. Through a short code placed in the source of a website, a user can monitor the performance of all their online properties. These tracking codes can also clearly indicate when multiple websites are run by a single user or entity — meaning they have been a particularly useful breadcrumb for open source researchers.
But there is a catch: Google is phasing out these codes and replacing them with ones that contain less data and make it harder to track who controls sites.
To address this problem, Bellingcat has developed a lightweight open source research tool—Wayback Google Analytics — which automates the collection of tracking codes and discovery of relationships between websites using copies of sites maintained by The Internet Archive’s Wayback Machine. This will help researchers sidestep recent changes to how Google manages its analytics data.
What is a Google Analytics Code?
Google uses a series of unique tracking codes to gather analytics data on websites. For over a decade, the most popular Google tracking code was the Universal Analytics (UA) ID: a small tracker buried in a script tag in a webpage’s source code.
A UA code looks like this:
UA-123456789-1
There’s a lot of useful information here. The centre code is a unique tracking ID issued to multiple websites managed by the same user or entity. The trailing digit separates multiple online properties owned by that entity (e.g., UA-123456789-1, UA-123456789-2, etc.).
Tracking UA codes is a staple strategy in the OSINT toolkit that is regularly used by investigators. In 2017, journalists in South Africa used Google Analytics data to uncover a coordinated disinformation campaign funded and managed by a member of the notorious billionaire Gupta family. In 2015, Bellingcat contributor Lawrence Alexander used this same method to connect dozens of websites pushing pro-Kremlin narratives about Syria and Ukraine to a single individual based in St. Petersburg, Russia. In both cases, shared UA codes between multiple web pages were a key data point in the investigation.
However, conducting such an investigation in 2023 is much more difficult due to sweeping changes in how Google manages its tracking IDs.
Google Analytics 4
Earlier this year, Google rolled out Google Analytics 4 — a new analytics framework that replaces UA codes with less uniform tracking IDs that are significantly more difficult to glean information from. It is no longer possible to obtain a new UA code, and most major websites have updated their tracking IDs to the new G and GTM codes.
This is bad news for investigators, as ProPublica reporter Craig Silverman explained earlier this year. While GTM and G codes are still worthwhile breadcrumbs, fewer online services keep databases of these trackers. Moreover, gone is the useful suffix that helps indicate when multiple sites are using the same tracking code.
There is some good news, though: Google says it isn’t planning to force websites to remove existing UA codes and, with time, more services will likely begin to catalogue G and GTM codes to help find relationships between websites.
In the meantime, we can still extract legacy UA codes from websites that continue to use them. Plus, we can also use the Wayback Machine to examine the source code of websites in the past and find any overlapping UA codes.
Using Wayback Google Analytics
Bellingcat’s Wayback Google Analytics automates the gathering of analytics codes and checking their usage on multiple websites. We can give the tool a list of websites, a time range and a desired output format (.csv, .json, etc) so we can quickly get a bird’s eye view of any shared data between websites.
You can read a more in-depth guide on usage and installation on our Github page, but let’s examine what a typical use case might look like. We’ll use a few (now-defunct) Russia-linked disinformation websites covered in an earlier Bellingcat investigation to demonstrate the tool’s usefulness.
- https://yapatriot.ru
- https://zanogu.com
- https://whoswho.com.ua
- https://adamants.ru
We’ll assume that we only want data from 2015 until the present. Since we’re looking for relationships between the websites, we’ll output the data into an Excel spreadsheet. Our command looks like this:
| wayback-google-analytics -u https://yapatriot.ru https://zanogu.com https://whoswho.com.ua https://adamants.ru -s 01/01/2015 -f yearly -o xlsx |
(There are a few other parameters included in this command — check out our README for a full list of options)
Wayback Google Analytics then generates an Excel spreadsheet that reports the analytics codes that were used by each website, as well as when they were first and last encountered in our search. In this case, these websites are no longer active, so we only have archived data obtained from the Wayback Machine.
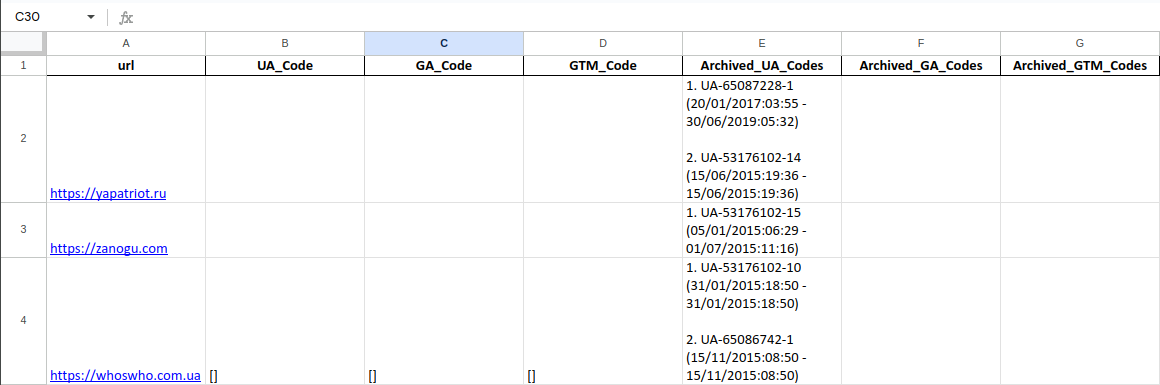
We can also view the data by code:
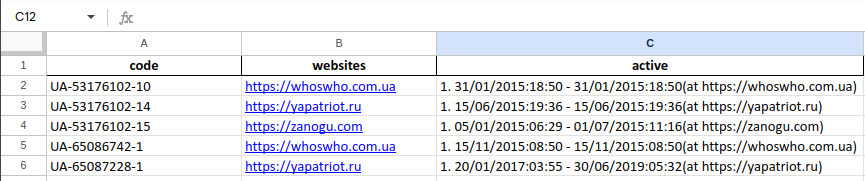
In the above data, “whoswho.com.ua”, “yapatriot.ru” and “zanogu.com” each share the same base code— indicating that they may be operated by the same entity.
Wayback Google Analytics is an open source project anyone can contribute to. Visit Bellingcat’s Github page to view contribution guidelines or look at this project’s active issues to get started.
Bellingcat is a non-profit and the ability to carry out our work is dependent on the kind support of individual donors. If you would like to support our work, you can do so here. You can also subscribe to our Patreon channel here. Subscribe to our Newsletter and follow us on Instagram here, X here and Mastodon here.

