
Analyzing Bin Ladin's Bookshelf
Translations:

Screenshot of ODNI.gov – Bin Ladin’s Bookshelf
This article was originally published on AutomatingOSINT.com.
On May 20, 2015 the ODNI released a trove of documents called “Bin Ladin’s Bookshelf“. This included all kinds of materials including letters he had written, books he was reading and other various bits of information. This document released piqued my interest primarily because I was interested to see what the most common thing was that Bin Ladin wrote about. I am fully aware that these documents are only a fraction of the material he had, but it seemed like a good exercise to stretch my Python legs and to learn a new API. This blog post will teach you how to analyze PDF’s (pretty useful all around really), and how to use the Alchemy API which is an extremely powerful data processing API that can do entity extraction, sentiment analysis, keyword extraction and a whole bunch of other stuff. All of this should be some solid additions to your OSINT toolkit. Let’s get started!
Installing Prerequisites
The first thing you are likely going to need is pyPDF. If you have read any of my previous posts you will use pip to install it:
C:\Users\Justin> pip install pypdf
Alright, done! Now let’s grab the Alchemy API prerequisites. The first step is to sign up for an API key. This will take 2 minutes and while you wait for it to arrive in your inbox let’s get the code downloaded. You can use their Git instructions or you can download from Github directly. All you have to do is unzip the folder and by now you should have your API key in your inbox, so drop into a terminal or command prompt and run:
C:\Users\Justin> cd alchemy_python C:\Users\Justin\alchemy_python> python alchemyapi.py APIKEY Key: APIKEY was written to api_key.txt You are now ready to start using AlchemyAPI. For an example, run: python example.py
Cool we are all setup now. I encourage you to run their example.py script to make sure everything is setup and running properly. You should see a pile of output from their script.
Downloading the Documents
Ok so confession time. I wrote the ugliest Python script ever to retrieve all of the documents that I was interested in. In the “Now Declassified Documents” section of the ODNI page, there are 103 documents. These were the primary documents I was interested in, but I encourage you to look at the other documents available on the site to see if you can expand your dataset. I did not want to manually download each PDF, this would bring shame and dishonour to our OSINT dojo for sure. So I created an ugly Python script to do it for me. Don’t tell anyone please, and very quietly enter the following code in a file called ugly_pdf_retriever.py and save it in your alchemy_python directory. You can download the file from here.
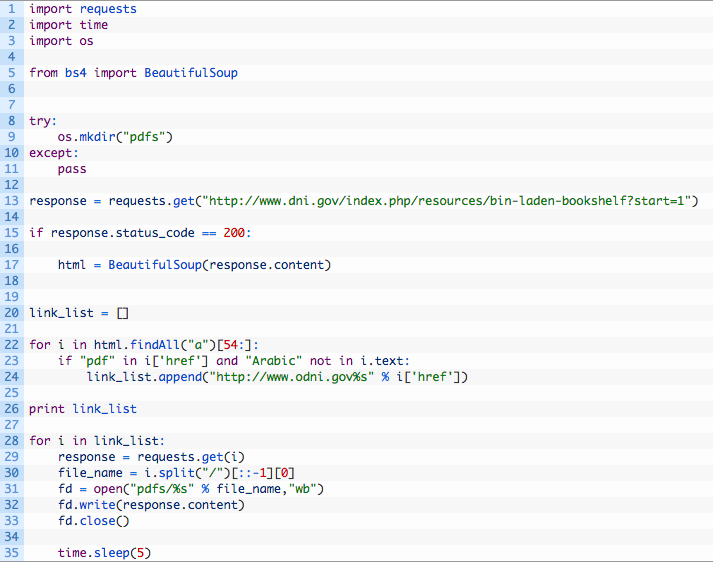
If you haven’t read my previous posts, shame on you, but mainly because you will need the requests and Beautiful Soup libraries to make this script work.
C:\Users\Justin> pip install bs4 C:\Users\Justin> pip install requests
Now let’s take a quick whirlwind through this thing:
- Line 8: create a new folder called “pdfs” so we can store them all and process them later.
- Lines 13 – 17: retrieve the ODNI page and send it to Beautiful Soup so that we can parse the HTML.
- Lines 22 – 24: it’s starting to get real ugly now. We walk through all links on the page starting at the 54th link and only pulling the PDF’s that are non-Arabic. We just build a list of links called: link_list.
- Lines 26 – 33: now we walk through the list, pull the PDF filename from the original link, and pull the document down from the ODNI site. From there we just write the PDF out to our pdfs directory and then carry on to the next file download.
Ok, I know it’s ugly but it works. Once you run it you should have a pdfs folder inside your alchemy_python folder, that is full of PDFs ready for us to analyze. In your career you, like myself, will write these quick and dirty scripts to automate tasks such as this. If you find yourself writing ugly ones like this, then congratulate yourself, your 15 minutes of coding saved you an hour or more of clicking on each document.
Processing the Documents
We are now ready to start messing with the PDFs we have downloaded. We are going to utilize Alchemy API’s ability to do entity extraction to see what the most common person, place or thing that Bin Ladin discussed in his letters. So effectively we need to open each PDF, extract all of the text from the document and then submit it to Alchemy to allow them to process it. For each document we process we will combine the results and then output some overall counts to tell us what the most common entities were. Let’s get started by creating a new Python script called ubl_bookshelf.py in your alchemy_python directory and punch in the following code (download from here if you prefer):
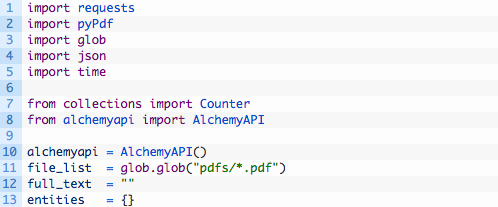
- Lines 1-8: we are just importing all of our required modules including the PDF processing module and Alchemy API.
- Line 10: initialize the Alchemy API so that we can use it.
- Line 11: the glob module allows us to retrieve a list of files from a directory that match a particular pattern. Here we are asking it to give us every file in the pdfs directory that has the .pdf file extension. Very useful little module that glob is.
- Line 12: we are going to use the entities dictionary to compile up all of our results from each PDF.
Now let’s add in our PDF reading and extraction code after the code we just wrote:
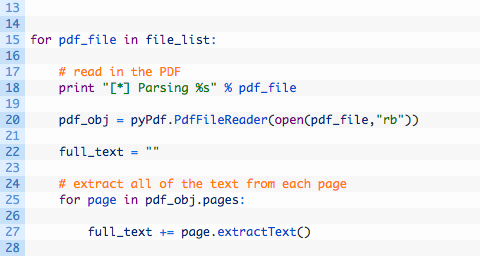
- Line 15: this is the loop were we walk through the list of PDF files that our glob call retrieved.
- Line 20: we initialize a new pyPdf object by passing in the file path and opening the file.
- Line 22: we create a blank string variable that will hold all of the extracted text so that we can hand it to Alchemy.
- Lines 25-27: here we walk through each page in the PDF and use the extractText function to pull out the text. We add the extracted text to our full_text variable.
Ok now let’s get our extracted text up to the Alchemy API! Keep adding to the ubl_bookshelf.py script, and make sure the next block of code is indented properly or it won’t work, refer to the source (here) if you need to verify.
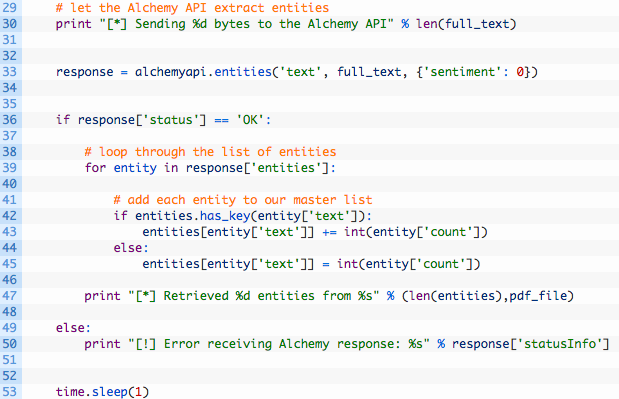
- Line 33: here is where we are making our Alchemy API call. We are letting it know that we are submitting text (the first parameter), we pass in our PDF text we just extracted (the second parameter) and we also disable sentiment analysis (I’ll cover in a future post).
- Lines 39-45: we loop through each entity returned by the API. Alchemy has a count member for each entity returned, so we make sure to tally all of the counts up in our entities dictionary.
- Line 53: we just want our script to take a 1 second breather. This is always something to be mindful of for any API you are running scripts against. Alchemy did not appear to have rate limiting, but I like to be on the safe side nonetheless.
Ok we are nearly done! Let’s add the following code to the bottom of the script:
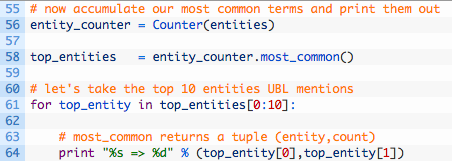
- Lines 55-58: we use the Counter class to load up our entities dictionary and then tell us what the most common term was.
- Lines 61-64: now we walk through the top 10 most common entities that we compiled. Of course you could change this to be the top 25 or whatever you please.
Now take it for a spin! We have included lots of useful output in the script to let you know that it’s working away. I won’t fully spoil the results but I can tell you that based on my run, the number 3 entity was “America”. Let me know what the top 2 were in the comments section below.
Wrapping Up
There were some key concepts here that are going to be useful in the future. One of the big ones is being able to process large numbers of PDF documents. Keep in mind these must be well formed (not scans) PDFs and at times this may pose a challenge. The other key concept was being able to use an API to perform entity extraction on these documents. You can use the results of this to build word clouds (want me to show you how? let me know in the comments or email me) or to build graphs or just to tell you some interesting statistics about a collection of documents.
